
完整的AI应用作品应包含以下几个部分:
1、项目简介
2、预期效果
3、操作流程
4、其他要求
具体情况及模板如下:
1、项目简介
1.1标题示例
30个字以内概述项目
示例1:
《使用安装AidLux的安卓手机,部署落地沃柑瑕疵检测AI应用》
示例2:
《基于人体关键点检测模型,通过AidLux实现AI皮影戏应用落地》
示例3:
《基于AidLux+Yolov5-Lite,全流程实现桌面级AI监测系统》
1.2、项目简介
用一段话描述你所做的项目,需明确项目目标、选用模型及关键指标、使用的优化方法和实现方式等内容。
示例1: 本项目通过语义分割技术,处理沃柑表面瑕疵检测任务。
瑕疵检测任务的瑕疵主要分为沃柑表面干疤、腐烂霉点、色斑三种,包括特征果蒂、果脐两种,最高mIOU 86.5%,模型选取deeplabv3+网络。
本文重点介绍如何使用AidLux进行沃柑瑕疵的语义分割部署。
示例2: 本项目通过运用PaddleHub人体关键点检测的深度学习模型,能够非常精确的提取出头部、肩膀、手脚等等16个人体关键点位置信息,将人体骨骼关键点进行连接,获取到人体的肢体骨骼,在骨骼肢体上覆盖皮影素材,将视频中连续帧进行转换,就可以实现“皮影戏”的效果。
皮影模型的肢体结构与人体构造结构基本一致,皮影戏的动作表演控制与人关节活动控制肢体动作也具有着极大的相似性。而目前基于深度学习的人体骨架识别技术可以获取图像中人体的关节位置,我们可以通过算法将人体关节位置解析人体肢体动作,再通过机器人(关节控制)对应皮影模型的肢体动作表演,从而可以实现一种新的皮影戏表演方式。
2、预期效果
用一段话描述你所做项目的业务逻辑和预期效果,介绍项目所使用的设备、软件情况,以及介绍AidLux是什么,在项目中起到的作用。
注:斜体加粗部分为作品中必要的内容。
示例1: 本项目使用利用安装AidLux的安卓手机实现,设备型号小米10,骁龙865,8+256。
在火车站、机场、地铁站、景区等公共场所,需要实时检测人流数量,当人流密度过高时及时预警,并实施导流、限流等措施,防止安全隐患。
在人流密度较高的公共场所,使用 Yolov5 + ByteTrack的多目标跟踪方案,可以实现不同场景下的人流数量统计,帮助场所的工作人员相应的管理方案。本项目可以实现在监控区域内识别人体,并统计区域内人数,在聚集达到一定数量时,发送消息到绑定的微信上。

对于开发者而言,AI项目中各种算法的数据集准备+模型训练+模型部署依然存在着不小的难度。AidLux的出现,可以将我们的安卓设备以非虚拟的形式变成同时拥有Android和Linux系统环境的边缘计算设备,支持主流AI框架,非常易于部署,还有专门的接口调度算力资源,极大地降低了AI应用落地门槛。
示例2: 本项目基于Aidlux+Yolov5-Lite+onnx,搭配微信提醒,全流程实现桌面级监测系统。
具体功能是可以检测人体在桌面上的一些活动,如识别出是在用笔写字还是在用鼠标,或者在使用手柄打游戏。
这个项目在现阶段网课比较普遍的环境下,可以很好的监测学生的学习状态。相较于网络摄像头更安全,不用担心隐私安全,也无需一直盯着监控。
当学生上网课的当检测出人体在使用手柄打游戏时,家长绑定的提醒类公众号上将会收到提醒:

本项目需要的硬件需求为:
1.装有pytorch框架的电脑
2.一台安卓设备,这里使用的是小米10,骁龙865,8+256。
3.usb摄像头(采集训练集数据用)
对于开发者而言,AI项目中各种算法的数据集准备+模型训练+模型部署依然存在着不小的难度。AidLux的出现,可以将我们的安卓设备以非虚拟的形式变成同时拥有Android和Linux系统环境的边缘计算设备,支持主流AI框架,非常易于部署,还有专门的接口调度算力资源,极大地降低了AI应用落地门槛。
3、操作流程
需要明确项目在算法选择、数据集采集、模型训练、模型部署等步骤和操作内容,其中涉及AidLux的部分,须以图文或视频的形式介绍具体操作方式。
注:发布在AidLux开发者社区文章的视频,需要先上传B站,然后粘贴视频链接。
具体视频发布步骤可点击链接查看:社区使用小Tips(一):如何在帖子内插入视频
示例1:
1.数据集准备
想要Train一个目标检测模型,训练集是第一步,所以我们先使用摄像头对训练集的图片进行采集。在本项目中我设置了三种检测物体(读者也可以根据需求自行改变):
pen——(笔)
mouse——(鼠标)
controller——(手柄)
我们使用usb摄像头来采集数据,首先我们先测试摄像头是否正常工作:

如果摄像头画面正常弹出,则说明usb摄像头工作正常,那么我们就可以进入到数据采集环节。在打开摄像头后,按's'保存图像,按'q'退出图像采集程序。
为了实现三个物体的监测,本项目大概采集了 两百多张照片 (读者可以根据检测物体个数、模型鲁棒性等因素自行决定数据集照片张数),这里展示数据集中采集到的一张照片。

2.数据集标注
在采集完图像数据之后,我们就进入到了数据的标注环节。本项目采用的标注工具为labelme,他的下载和使用非常简单,只需一下两步: pip install labelme labelme
唤起labelme图像界面之后,单击左上角的file,我们需要对其进行一些设置:
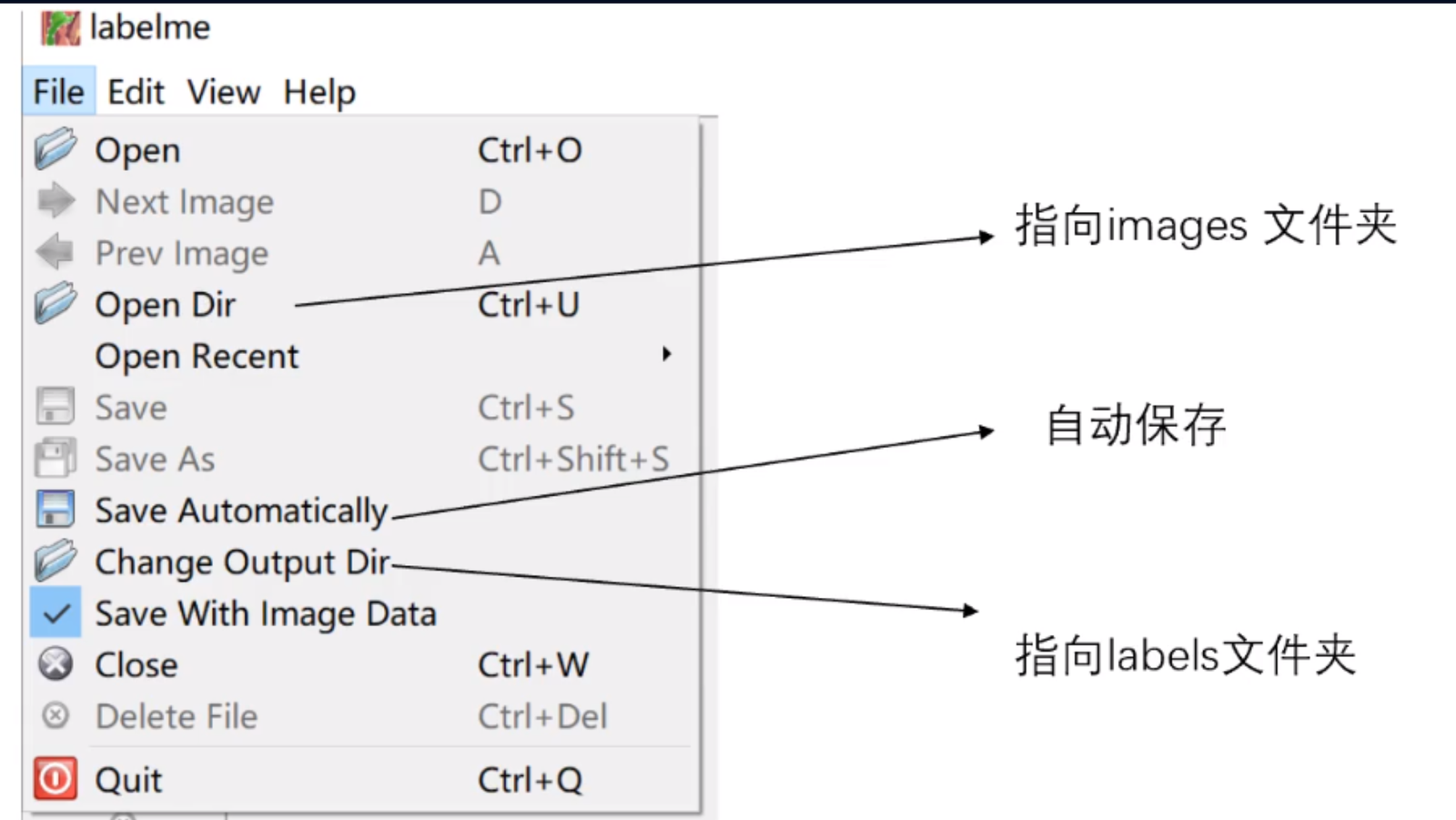
在配置好我们的输入images文件夹和输出labels文件夹的路径之后,我们就可以进入到标注环节,create rectangle创建矩形框来框住我们图像中的物体。标注的话是个 体力活,体力活,体力活 。 在标注完成后,我们图片的json文件是长这样的:
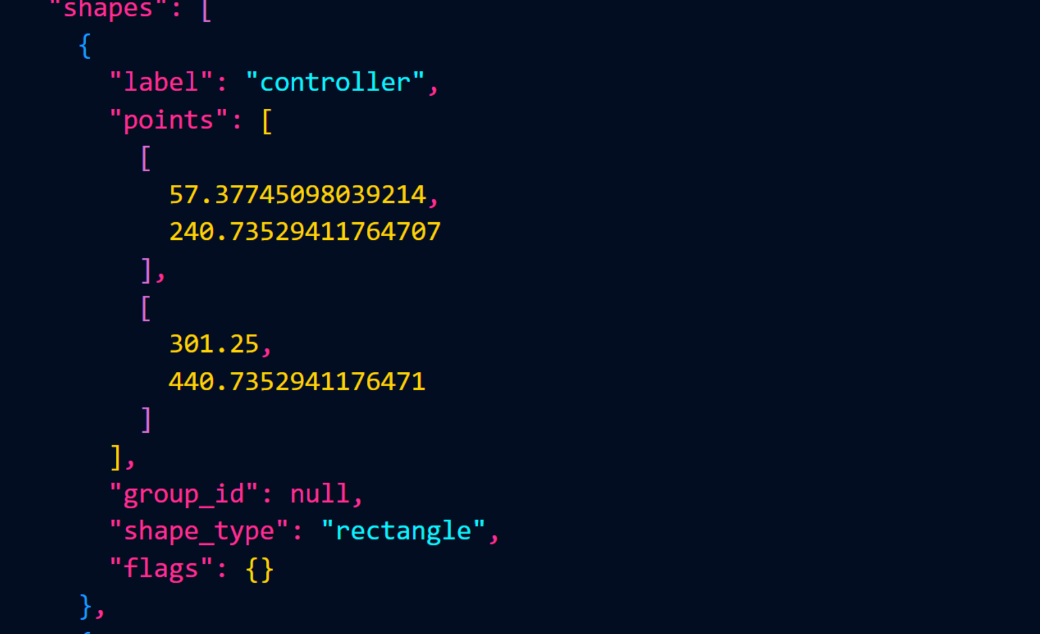
可以看到这里表示bbox是图像中的真实值,而我们送入yolov5-lite里面训练的bbox是需要归一化之后的数据,所以我们对数据经行归一化,生产符合yolov5-Lite训练格式的文件。同时我们也根据ratio分割训练集和测试集。
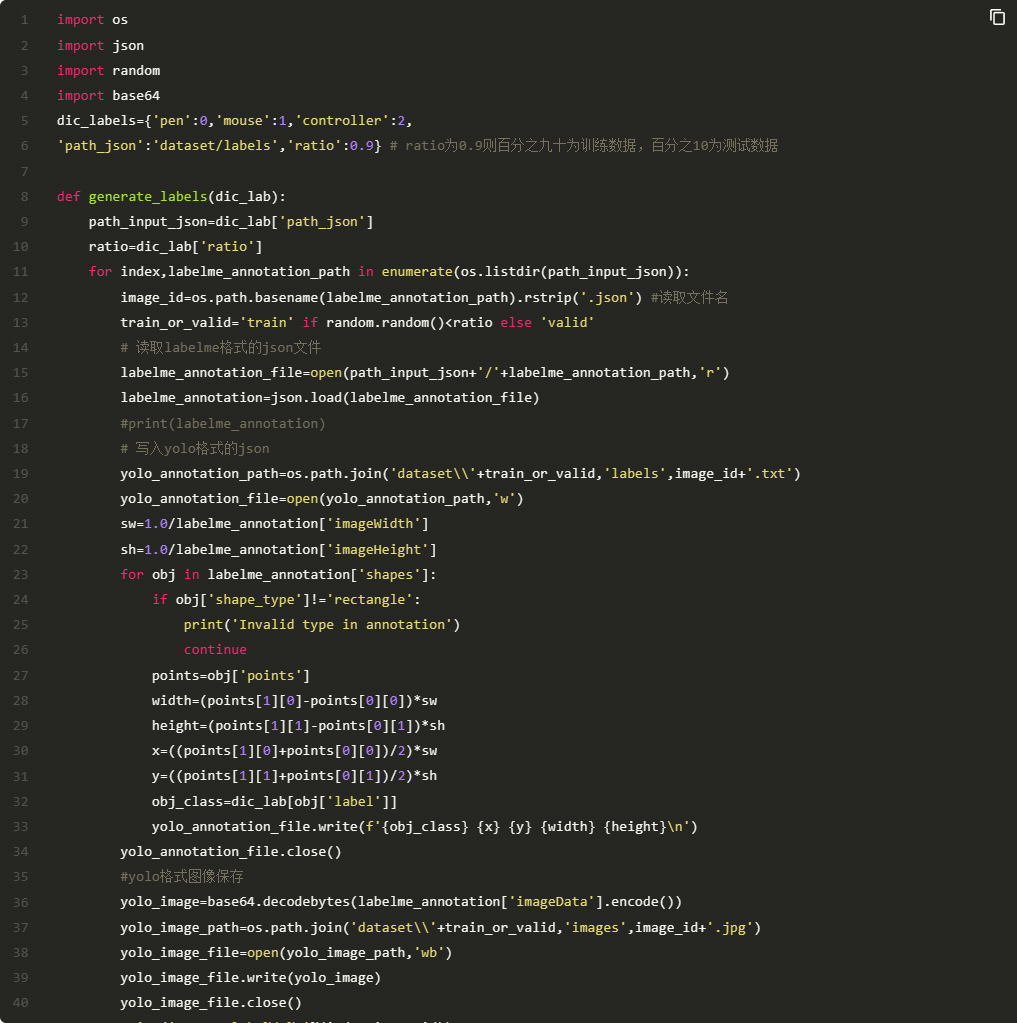
3.数据集训练
yolo5-Lite的github项目地址为:https://github.com/ppogg/YOLOv5-Lite。在准备好yolo格式的数据集之后,我们就可以进入到训练环境。训练环节有三个需要注意的点:
pretrained model
mydata.yaml
config
3.1 pretrainde model
pretrained model预训练模型是我们模型的初始参数,如果不使用pretrained model,网络的收敛速度会慢很多,训练效果也会差很多。本项目使用的pretrianed model为v5lite-e.pt.
3.2 mydata.yaml
mydata.yaml是数据集中的一些信息。其中包含了train和val的path以及训练集中存在的所有class
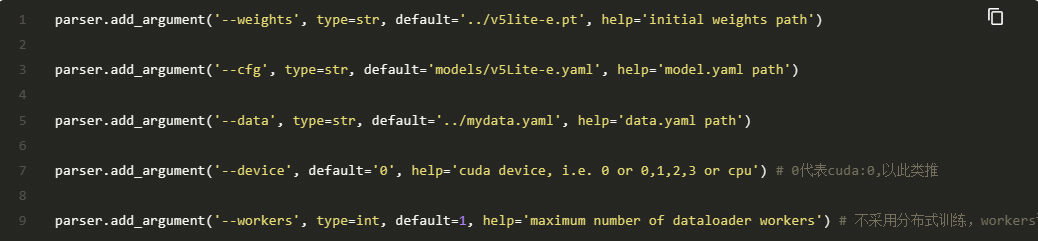
3.3config
每一个模型都是需要配置config的,在此记录一些基本操作和yolo5Lite配置过程中遇到的问题。
首先是基本配置:
再是包的配置,这里提一个windows系统下极难安装的pycocotools包,根据一下步骤安装即可: 先从网上下载pycocotools的安装包 https://pypi.tuna.tsinghua.edu.cn/simple/pycocotools/ ,建议下载2.0.4版本。 进入到解释器的文件夹目录,我这里是miniconda3/envs/pt_env,然后解压下载的安装包,进入到安装包文件夹,并在在此处打开终端,输入如下命令:

终端出现成功安装提示。
在配置完参数之后,直接运行trian.py即可。训练完成之后会在runs里生成exp_n文件夹来保存训练模型参数和训练过程的一些数据。
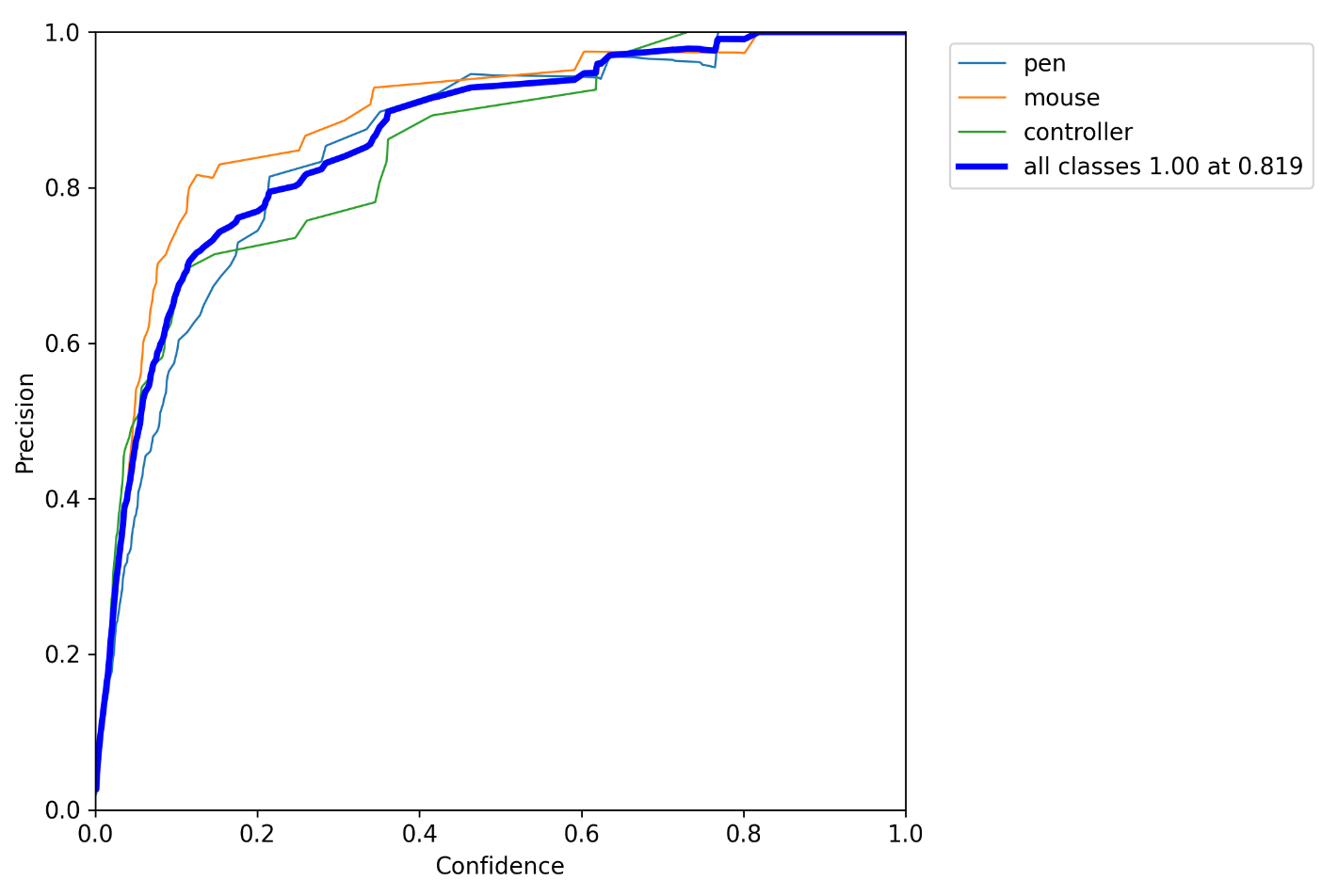
4.电脑端模型推理
在模型训练完毕之后,我们需要在电脑端先对pt模型文件进行测试。在模型推理过程中,可能会出现如下报错:
'Upsample' object has no attribute 'recompute_scale_factor'
我们只需进入对应文件
"C:\Users\Levite_Lou\miniconda3\envs\pt_env\lib\site-packages\torch\nn\modules\upsampling.py"
将153,154行替换为如下内容即可
return F.interpolate(input, self.size, self.scale_factor, self.mode, self.align_corners)
电脑端模型推理代码如下:

因为我们最后是要部署到手机摄像头上,所以我们现在电脑上启用摄像头看看检测效果:

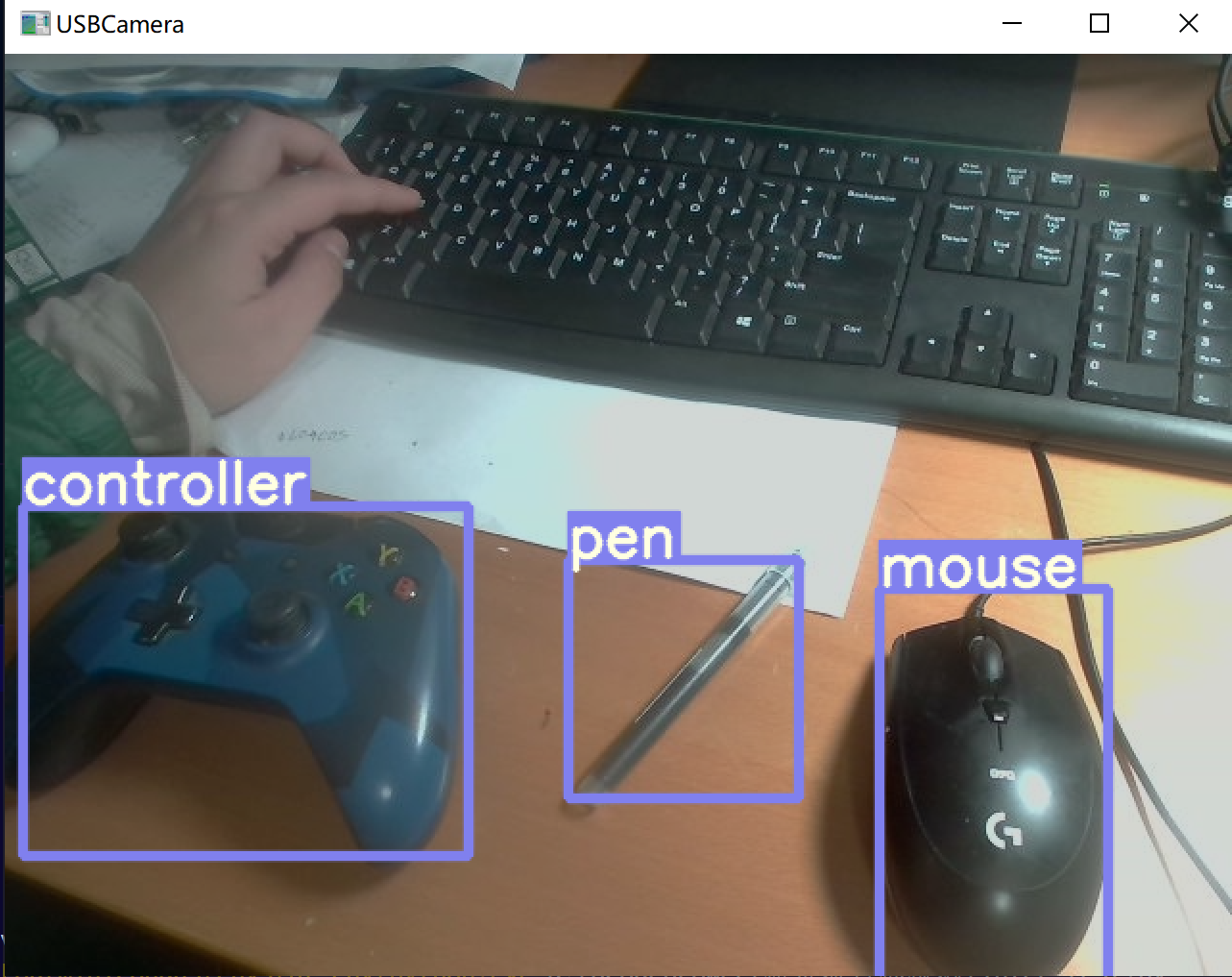
5.导出onnx文件
ONNX(Open Neural Network Exchange) 是一种表示神经网络模型的 IR(Intermediate Representation),它定义了一套可扩展的计算图以及一系列标准的数据类型和算子。当前大多数训练、部署框架以及硬件厂商的推理加速引擎都支持 ONNX 格式。
本项目也使用了onnx文件在Aidlux进行推理,我们先将best.pt文件导出为best.onnx:
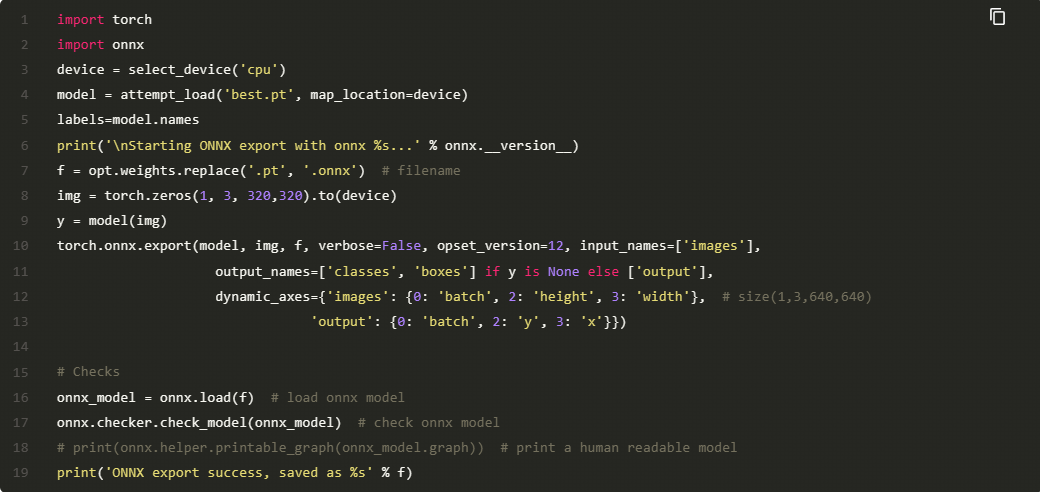
best.onnx文件导出成功,接下来我们就可以在Aidlux上进行推理测试了。
6.AidLux端模型推理
因为我们导出的是onnx类型文件,所以我们需要先在Aidlux上安装onnxruntime包,包的安装非常简单,只需打开Aidlux的app界面,其中有一个onnxruntime1.8.1版本,点击安装即可。
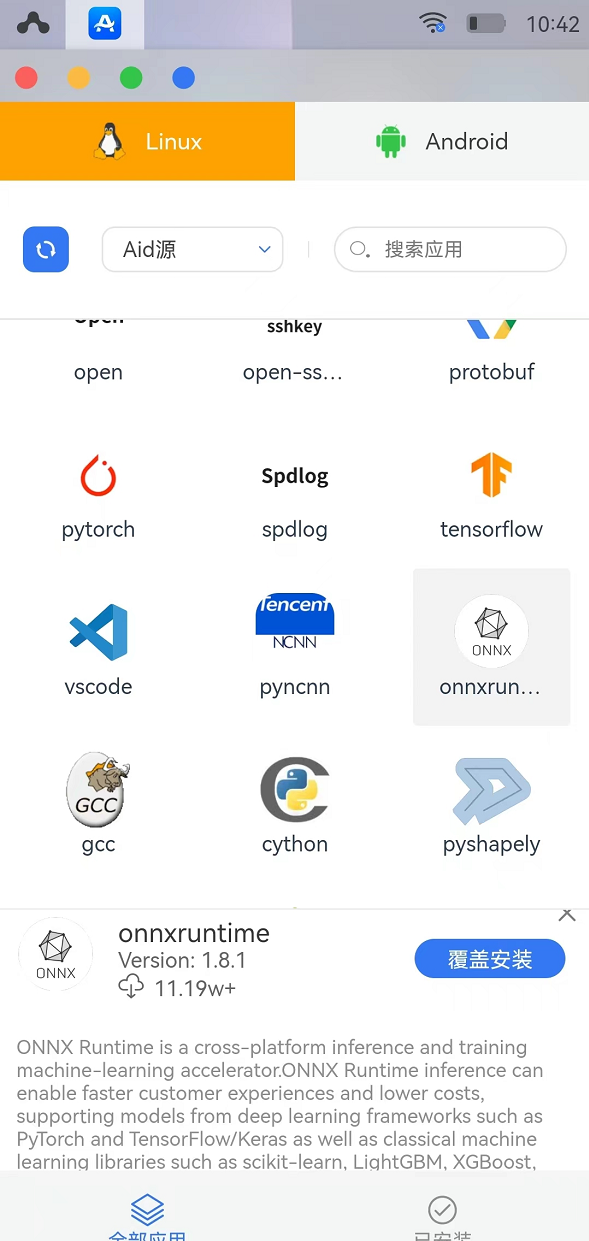
在安装好了onnxruntime之后,我们将会使用其框架读取我们在电脑端导出的best.onnx文件进行推理,在Aidlux端进行推理的代码如下:
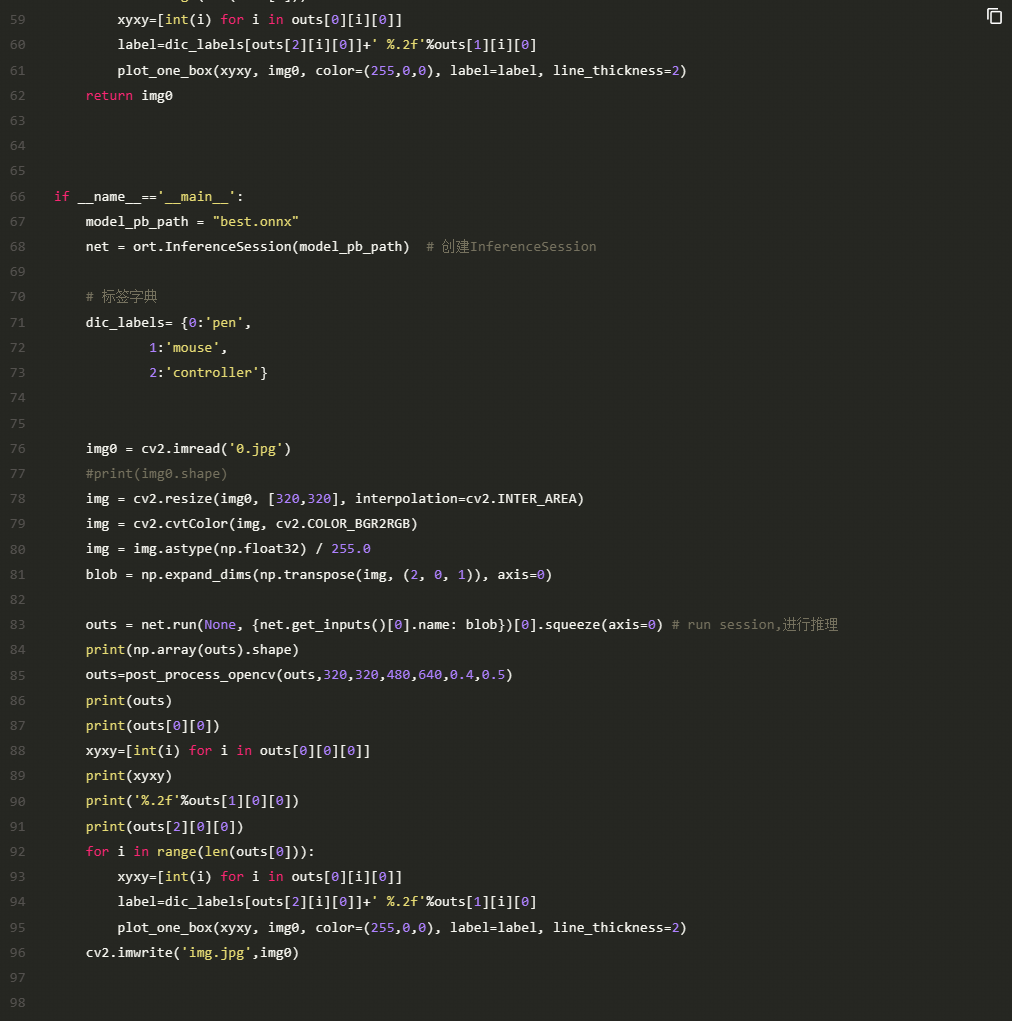
这边我使用的样本图片为训练集的第一张图片0.jpg,在Aidlux端利用onnxruntime推理效果如下:

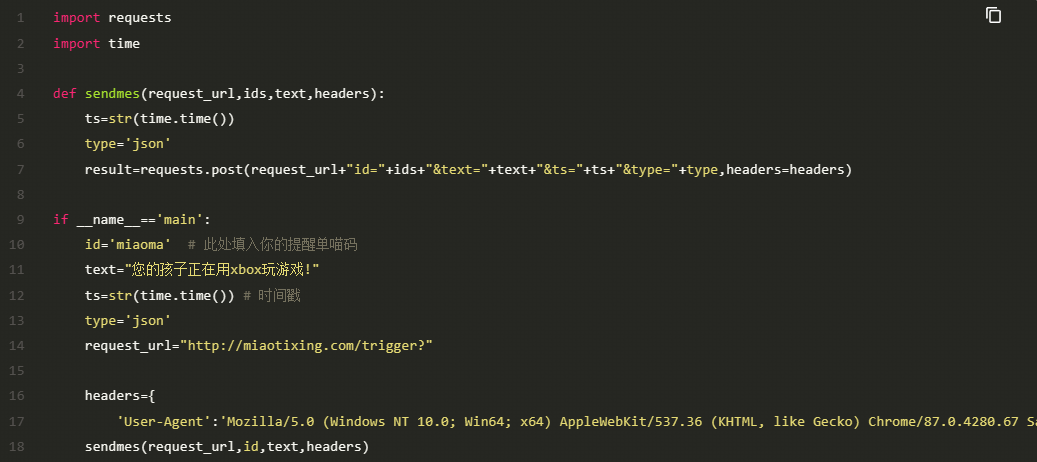
7.喵提醒
当我们的桌面级监测系统检测到笔和鼠标时,说明孩子在正常的进行网课学习。当监测到手柄时,我们希望系统向家长的手机发送告警信息,此项功能我们使用喵提醒公众号来实现。
具体流程为: 关注喵提醒公众号—>点击右下角个人中心——>点击下方我的提醒——>新建提醒单——>复制喵码
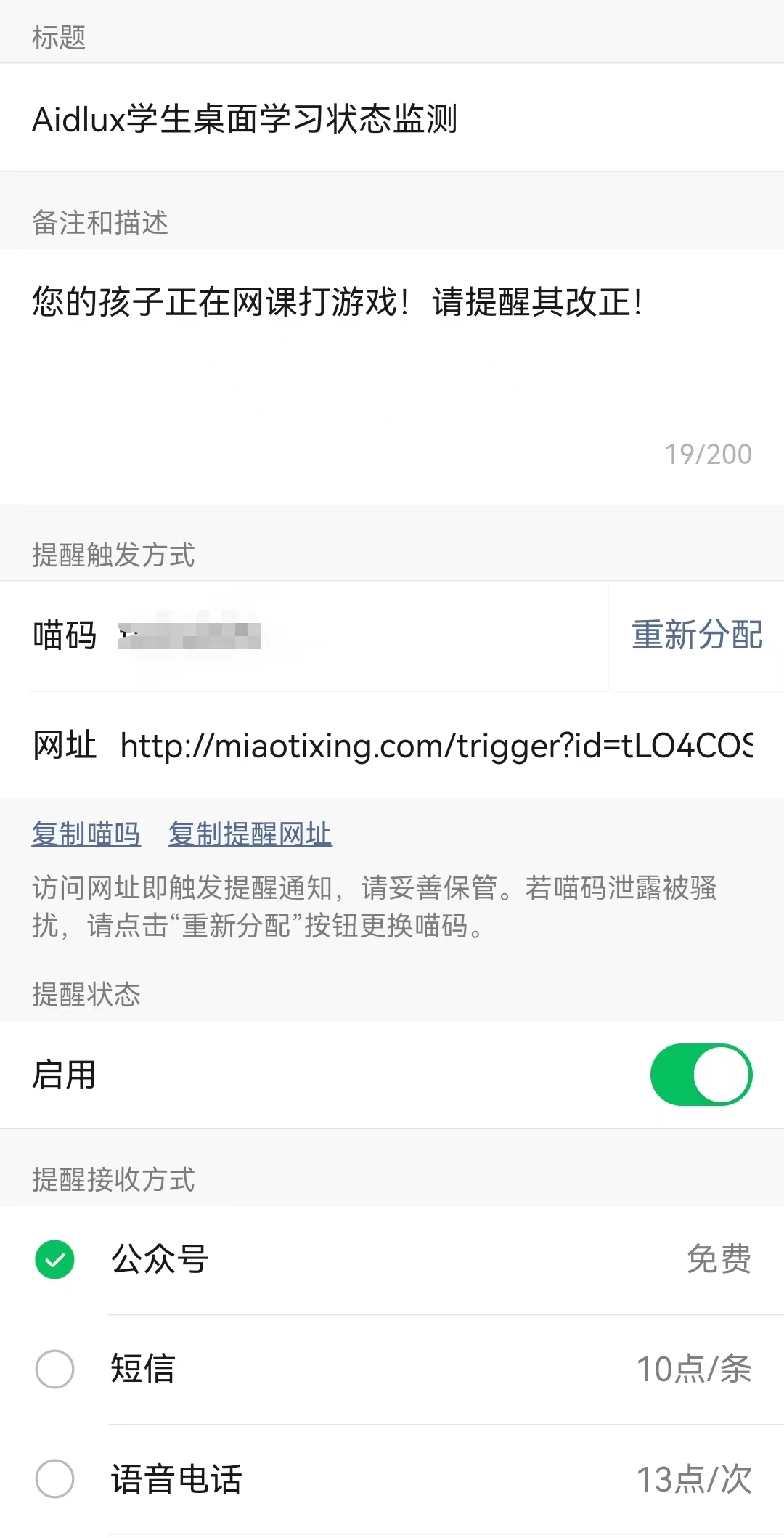
在成功创建提醒单之后,可以在AidLux端先进行简单的测试:
8.AidLux端摄像头监测实现
在有了前面的准备之后,我们就可以很轻松的在Aidlux端利用Onnxruntime框架实现部署,AidLux端的主启动文件代码如下:
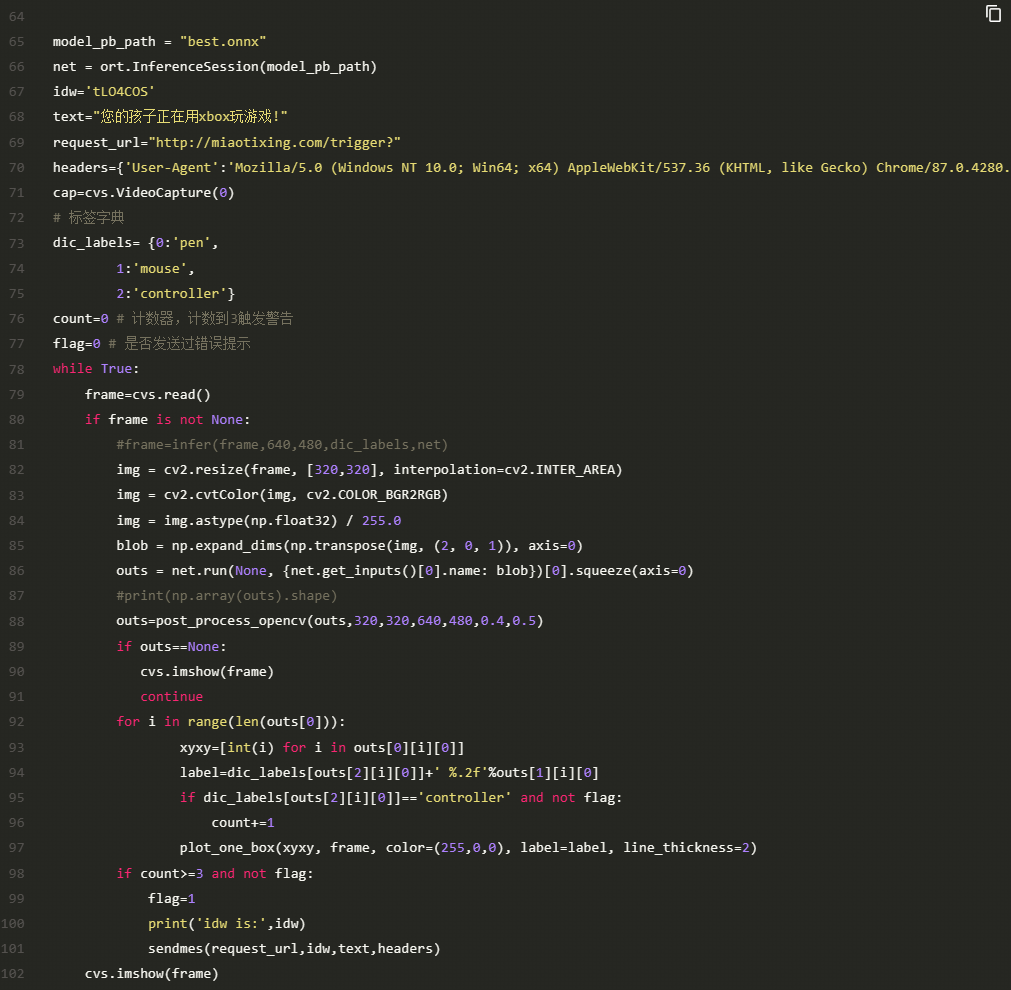
cvs.VideoCapture(x)函数将会指定打开的摄像头,0为设备后摄,1为设备前摄,也可以使用usb摄像头配上usb转typec转接口接入手机,然后2为接入的usb摄像头。
9.视频演示
对AidLux感兴趣的同学,可以加入AidLux官方交流群,群内有官方工程师和AI行业的大神在线互动。
示例2:
2.目标检测:yolov5推理测试
2.1 Yolov5代码下载
Yolov5的官方链接为:https://github.com/ultralytics/yolov5
2.2 安装Pycharm+Conda+Python
PS:如果电脑上已安装好Pycharm和Conda环境,可以先跳过2.2章节,查看2.3章节。
图像算法入门,大白首推Python语言进行编程,超级简单方便。
而在编程中,为了便于管理代码,推荐大家使用Pycharm软件。
考虑到很多人刚入门时,通常使用Window环境。
所以可以在Window安装Pycharm软件和Python语言,此外因为不同项目中,Python版本可能都不相同,因此可以安装一下Conda环境。
多个软件安装的流程,可以参考大白的文章,链接:https://www.jiangdabai.com/422。链接中也包含了安装Conda环境、Python、Opencv方面的资料,可以按照说明一步步下载学习。
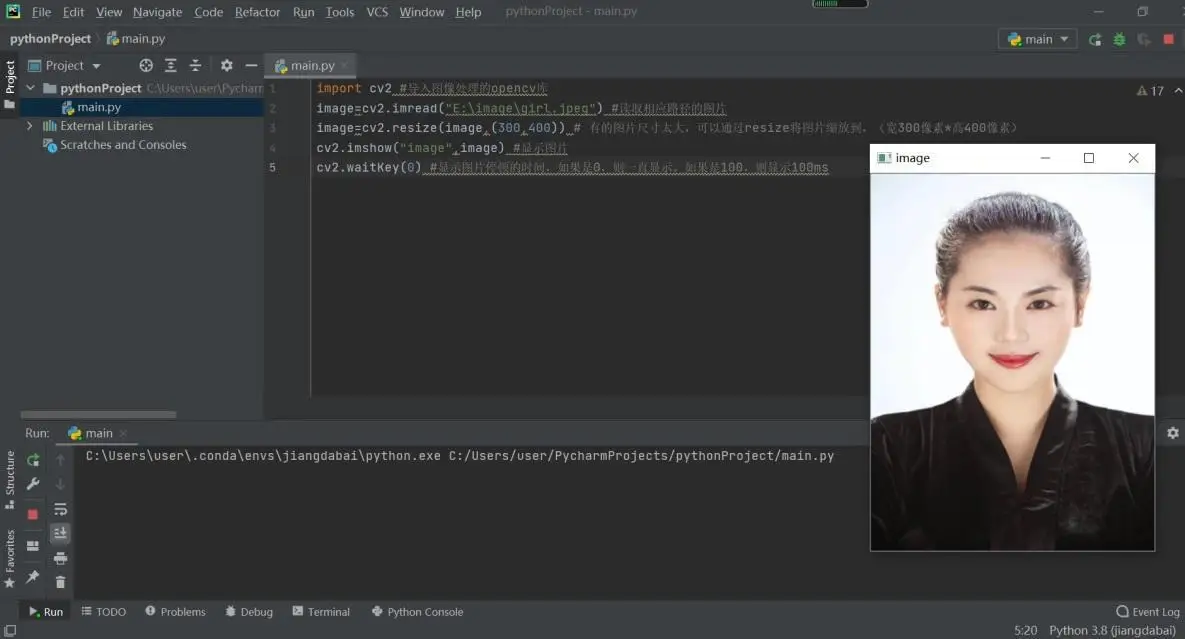
当然如果使用linux系统,也是一样的,可以检索下教程先把Pycharm软件、Conda环境等安装起来,最终可以实现Opencv读取并显示一张图片。
2.3 Yolov5推理测试
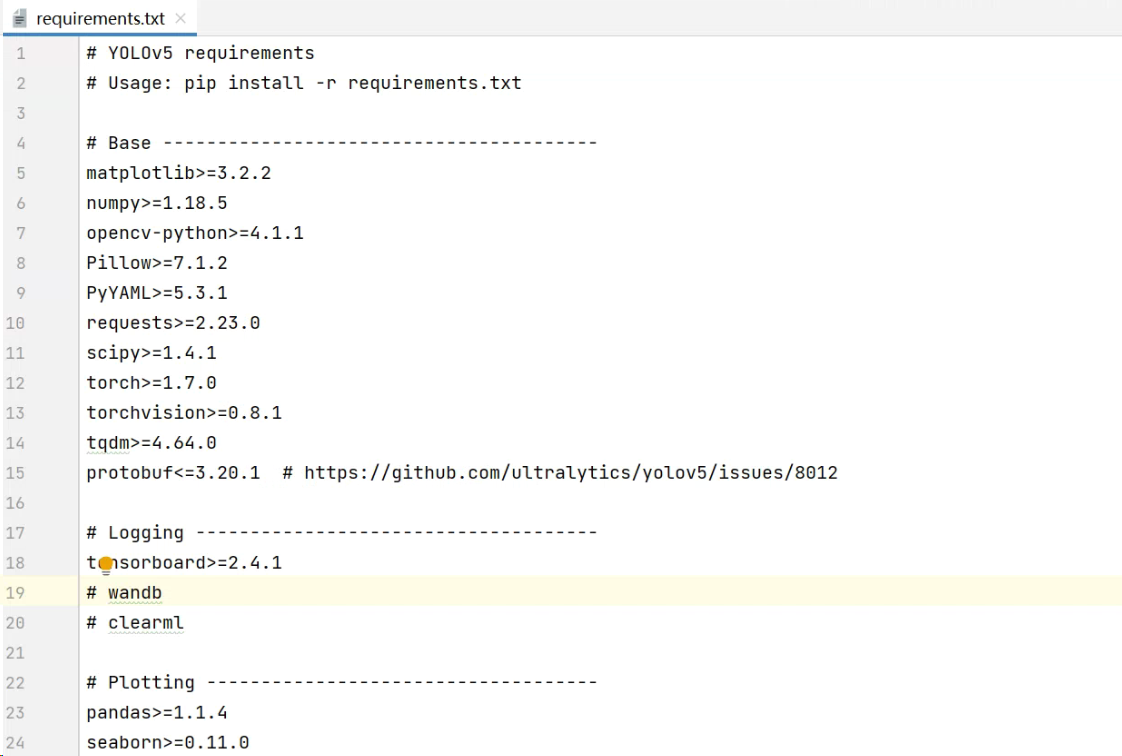
在下载完前面整套代码后,首先按照其中的requirements.txt中的说明,下载一系列的依赖库。
为了测试各类依赖库是否正常,可以使用Yolov5的推理代码,进行推理测试。
主要修改一下detect.py文件里面模型文件的路径。
运行代码后,对于data/images里面的案例图片,会进行推理测试,生成效果图片后,会放在run/detect/exp文件夹里面,看到推理效果。

2.4 Yolov5图片及视频检测
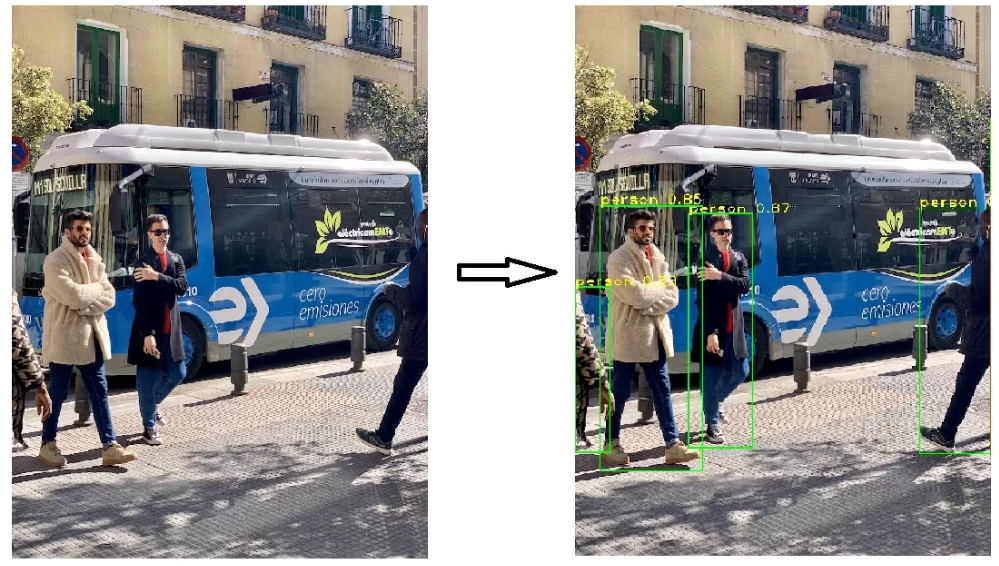
Yolov5推理时,使用的是CoCo数据集训练的模型,总共有80个类别。
因此在我们的图片中,可以看到检测出人体和车辆,而在本文要做的家庭安防告警系统中,主要对于人体进行检测,所以我们修改下detect.py,只输出人体的检测框。

为了大家更好的理解推理的过程,大白将detect.py的代码进行简化,针对图片推理和视频推理的过程,编写了两个脚本。
detect_image.py主要是图片推理的代码,detect_video.py主要是视频推理的代码,都放在主文件的代码中。
(1)图片推理服务
当运行detect_image.py代码时,在后处理时,添加了过滤非人体类别的判断。
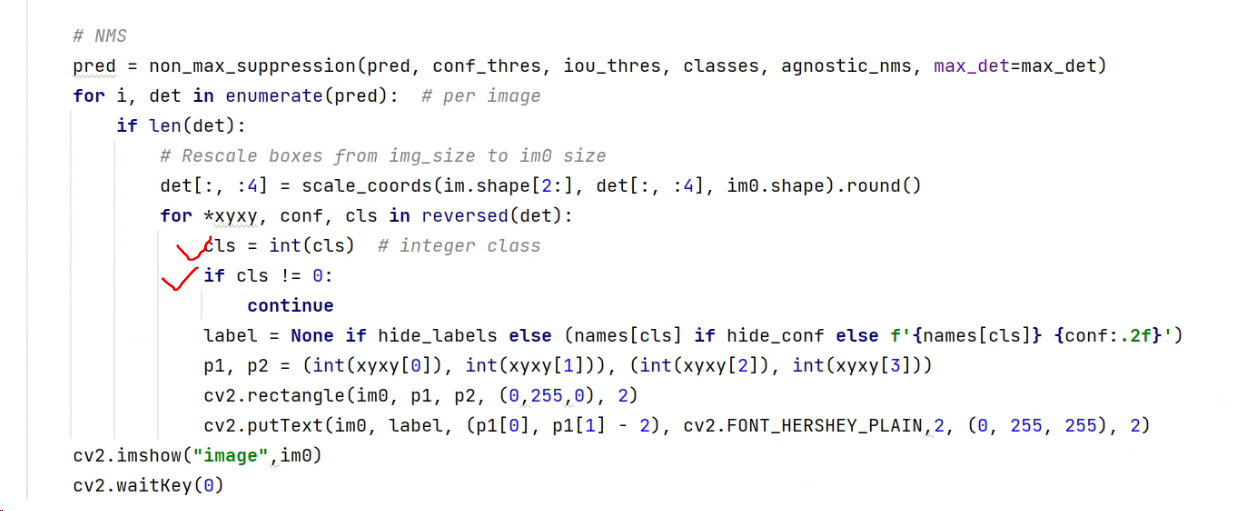
因为person的类别在CoCo中是0,所以运行代码时,会得到只有人体的检测结果。
2)视频推理服务
从对图片的推理,延伸到对于视频的推理,也是一样的。
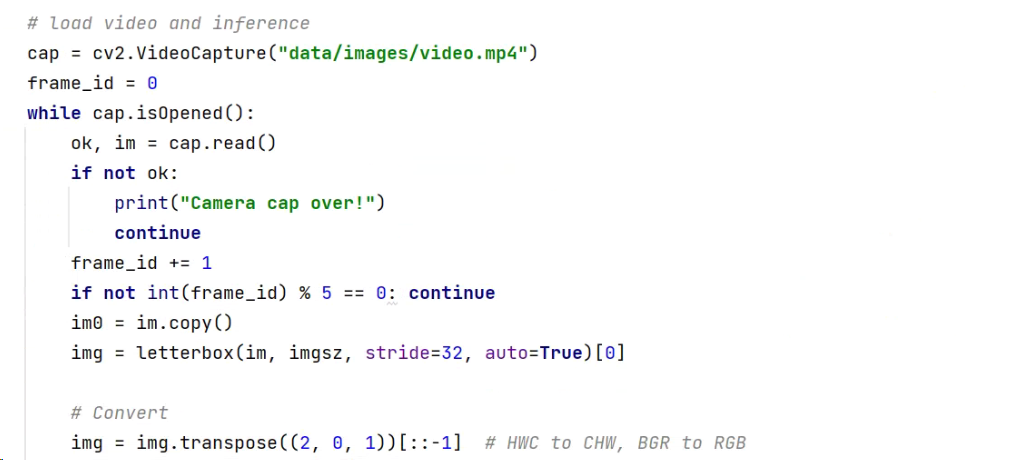
主要将读取图片的部分,修改成读取视频的部分,最终可以对data中的video.mp4进行人体检测。

3.图片云服务:七牛云图片上传下发 在实际的业务场景中,是监测无人的场景下,是否有人闯入。比如晚上睡觉的时候,出差不在家的时候。 当然,这是大白的一种场景应用,大家也可以根据自己的想法,创作各种其他的应用。 当有人违规闯入时,我们需要实时查看违规人员的图像画面,因此需要将检测结果的图片,上传到云服务器中,并且生成一个外链,进而发送到我们的微信上,便于实时查看。 这里提到的云服务,其实大白也尝试了阿里云、腾讯云、七牛云,综合比较下来,七牛云性价比最高,因此在本章节中,大白将整个七牛云的操作流程,代码操作,一步步的详细描述出来,大家逐步对照即可。 具体步骤参考: 4.微信提醒:喵提醒服务开发 到此,我们可以使用Yolov5实时监测是否有人体入侵,也可以得到图片的外链,但是还需要将图片链接实时发送到我们的微信上,这样我们才知道是什么人进入我们的私密空间。 当然,我们个人的微信是没办法接收消息的,所以这里主要通过“喵提醒”的自动提醒功能。 *具体步骤参考:https://community.aidlux.com/postDetail/786 *
5.PC代码整合:人体检测+七牛云+喵提醒 前面使用了Yolov5实时检测、七牛云服务器上传效果图片、喵提醒三个部分,单独的部分我们都会了,再试一下把三者整合在一起,看一下整体的效果。 为了便于大家学习,大白还是整合成两个代码,一个是相对比较简单的,对于图片进行检测操作。另一个是对于视频进行检测提醒操作。 5.1 图片检测告警操作 图片检测告警的脚本在detect_image_qiniu_miaotixing.py文件中,其中添加了对于人体检测的判断,即图片中的person=1,当图片中检测到人体时,自动保存检测到的图片,并将图片发送到七牛云,并通过喵提醒发送到手机上。
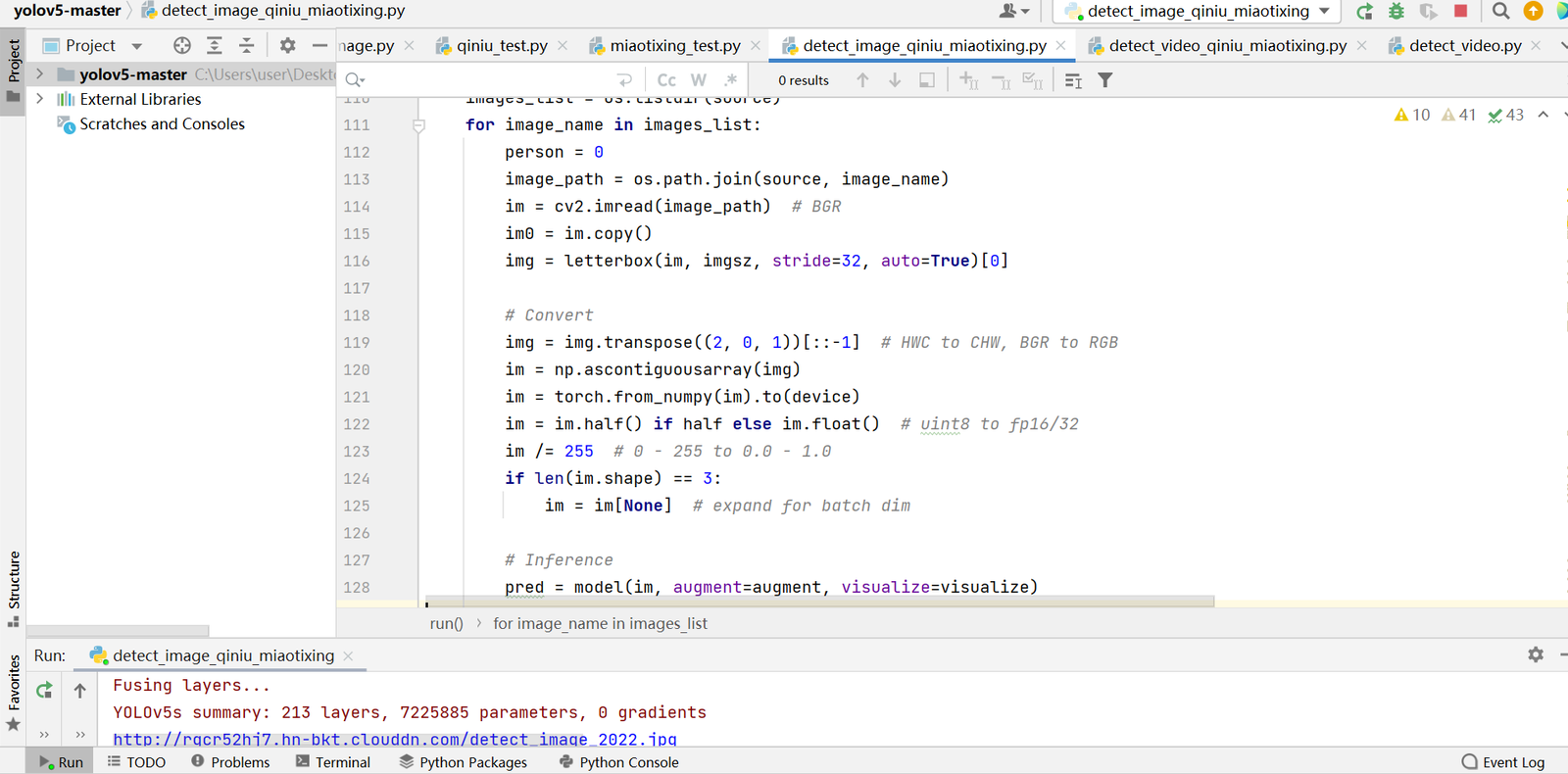
5.2 视频检测告警操作
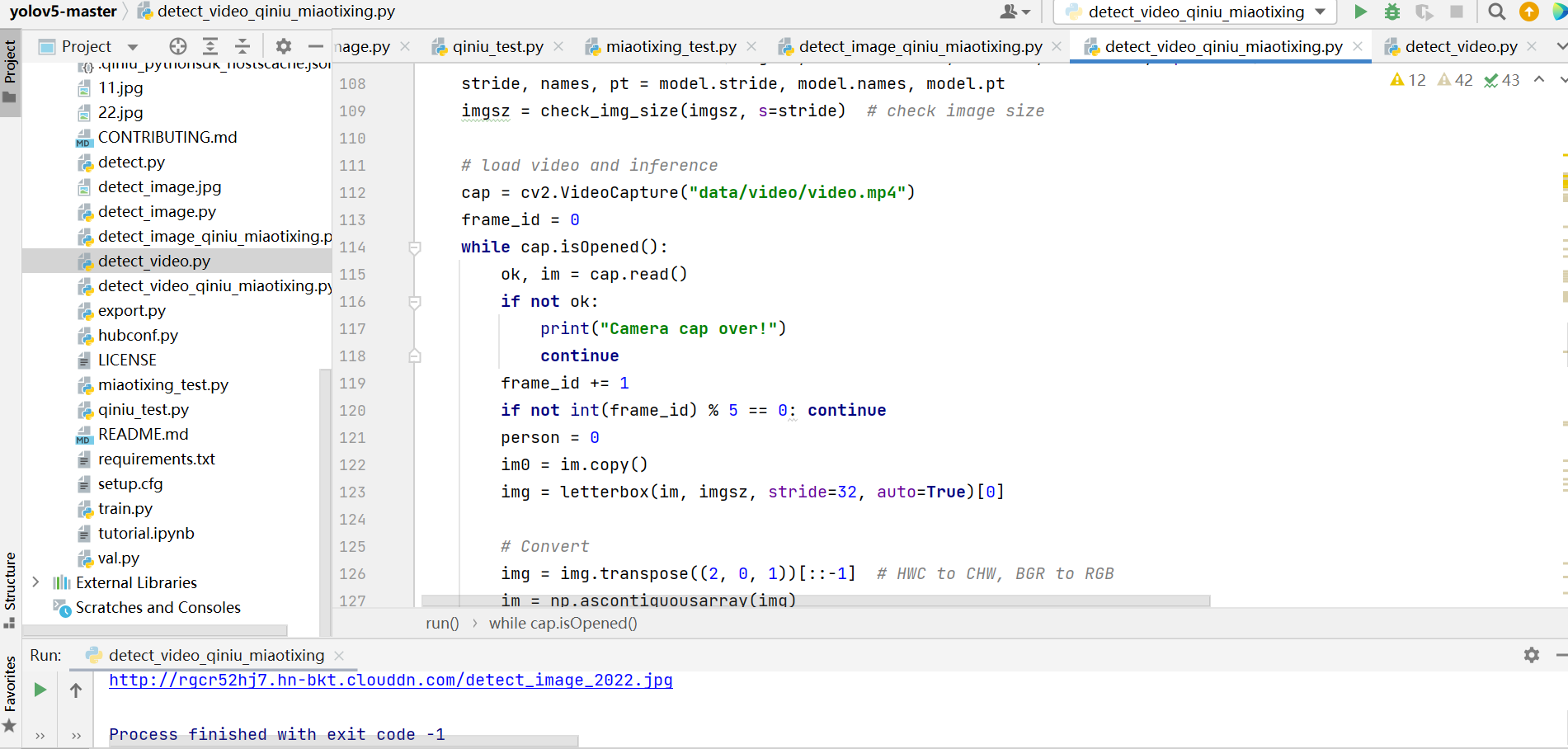
视频检测告警的方式和图片类似,只不过读取的是视频信息,视频检测告警的脚本在detect_video_qiniu_miaotixing.py,运行后可以得到视频中告警的图片。
6.Android部署:AidLux平台软件部署
前面是通过PC端电脑实现业务逻辑的整个流程,但是在此项目实际使用的时候,我们并不是在PC端进行的项目部署,而是运行在手机端,或者边缘设备上。
常规的方式,应用在手机Android时,需要将PC上编写的代码,封装成Android SO库(C++),经过测试后,封装JNI调用SO库,最终在Android上使用Java调用JNI,最终再进行测试发布。
因此我们可以看到,需要一系列的工作人员参与,比如C++、Java、Python的工程师。
但是大多数算法人员可能会用Python更多一些,比如上面编写的整套算法,怎么快速落地成一个Android产品呢?
在此过程中,大白找到了一款Aidlux平台(https://aidlux.com/),使用Aidlux后,可以将PC端编写的Python代码,直接迁移到Aidlux平台,测试发布,其中只需要编写Python代码即可,节省了C++、Java人员的工作量。
6.1 下载安装AidLux软件
AidLux软件使用非常方便,可以安装在手机、PAD、ARM开发板等边缘端设备上。而且使用Aidlux开发的过程中,既支持在边缘设备的本机开发,也支持通过Web浏览器访问边缘端桌面进行开发。
而在本文中,采用手机边缘端和Web端两种方法结合的方式,进行开发。
(1)下载AidLux软件
首先在安卓手机上下载一个AidLux软件,大白的手机是华为手机,在华为手机的应用商城中搜索“aidlux”,即可安装下载。如果有其他品牌的手机,在相关的应用商城中,都可以下载到相应的aidlux软件。
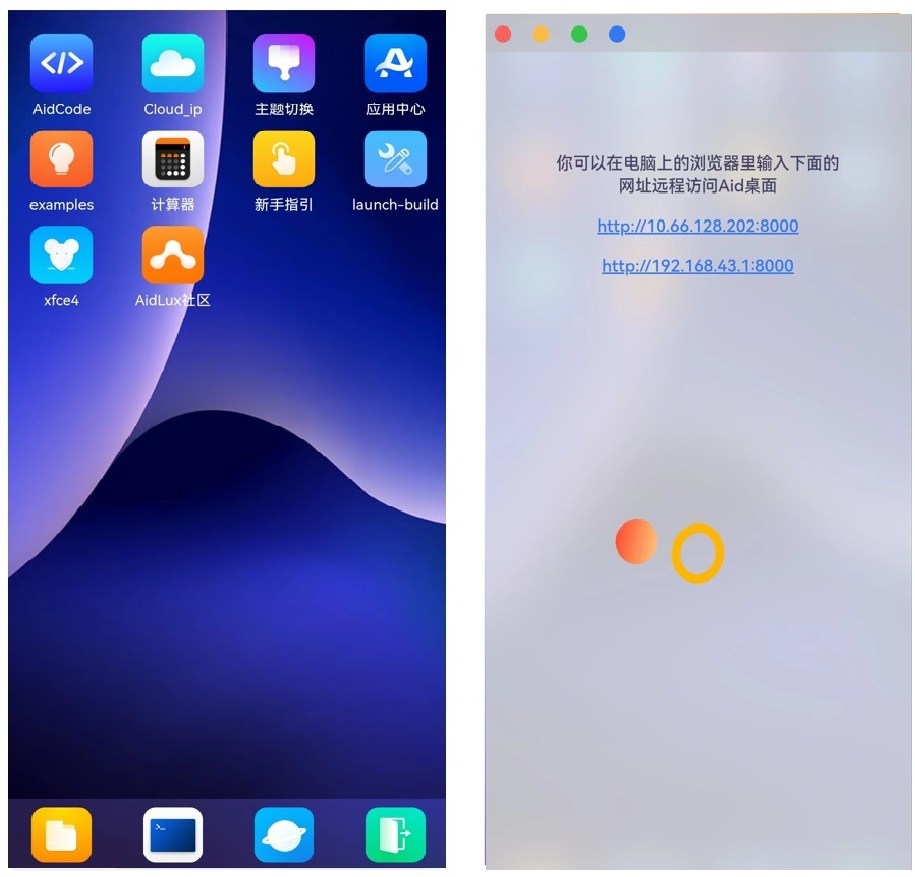
(2)将手机的wifi网络和电脑的网络连接到一起,打开安装好的手机上的AidLux软件,点击第一排第二个Cloud_ip。可以看到,手机界面上会跳出可以在电脑上登录的IP网址。
在电脑的浏览器上,随便输入一个IP,即可将手机的系统投影到电脑上,任何操作和代码编写都是完全数据共通的,这样我们就可以将PC端的操作,直接应用到Aidlux的App中了。
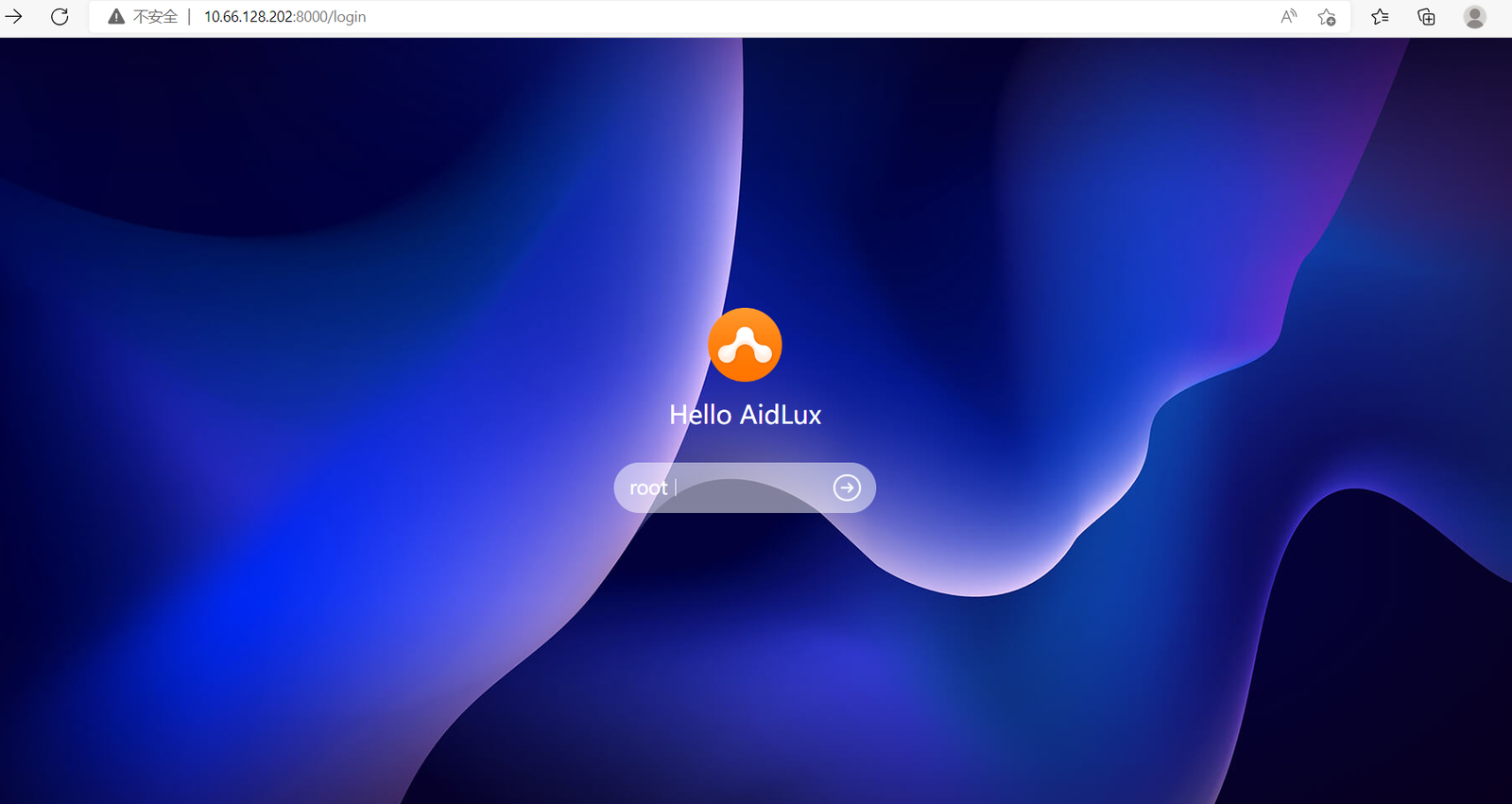
(3)输入IP后,在电脑端的浏览器中,可以跳出Aidlux的登录页面,默认登录密码是“aidlux”。
需要注意的是,使用aidlux的PC端的时候,手机的aidlux软件也要相应的打开,保持联通状态。
6.2 AidLux边缘侧使用案例
当然我们也可以直接看一下aidlux内置的很多AI方面的案例,点击右下角的examples应用,里面内置了基础的18种AI应用。
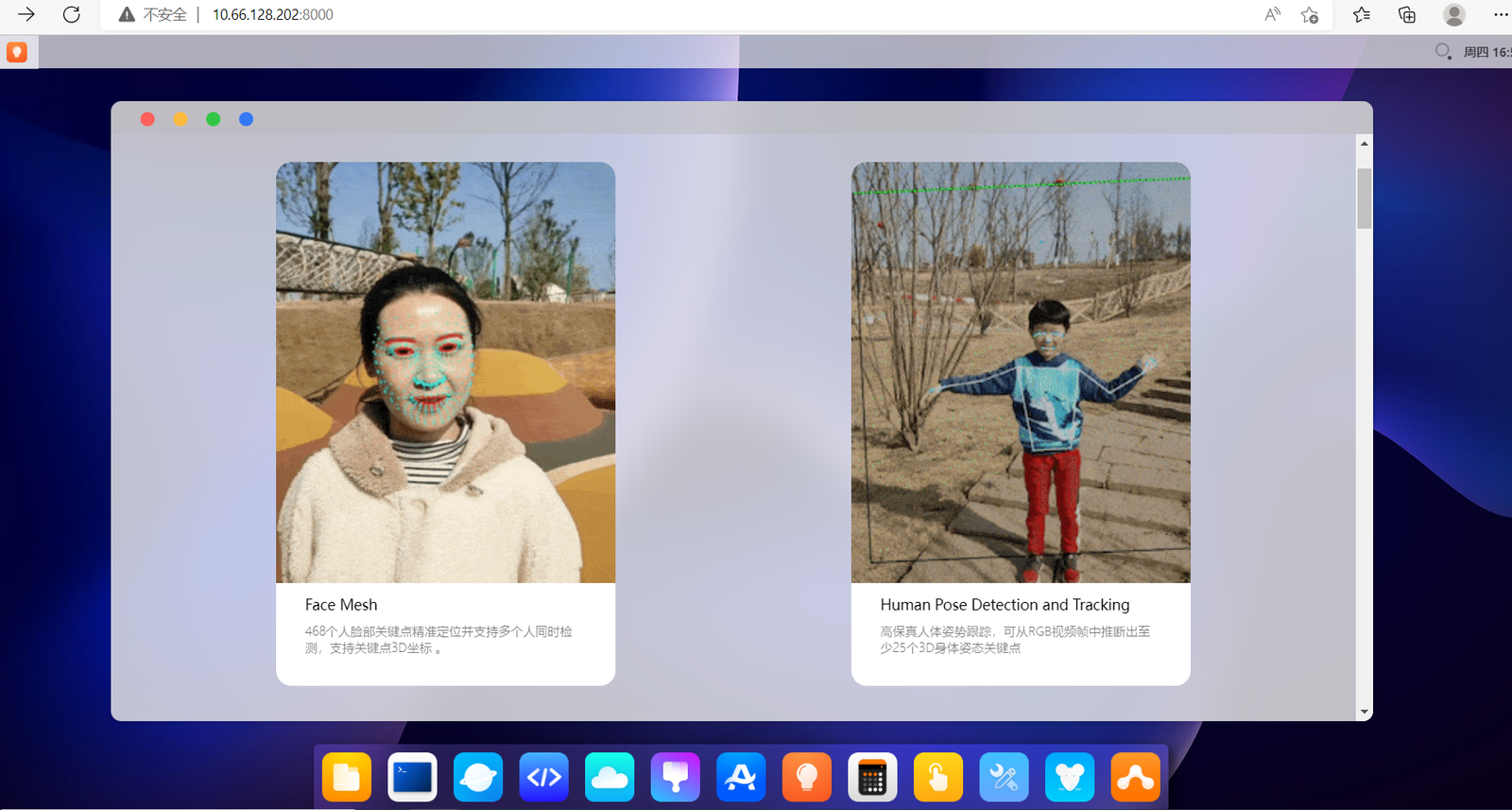
我们可以尝试一些人脸关键点的应用,点击PC端中的应用。

可以看到跳出的应用的代码,大致浏览一下,和我们的Python代码基本都是一样的,不过有的同学也会发现,多了一些不常见的库,比如cvs、aidlite_gpu,这些都是aidlux内部优化的函数,可以极大的提升手机芯片的算力使用率。
点击运行的小图标,选择“Run Now”。
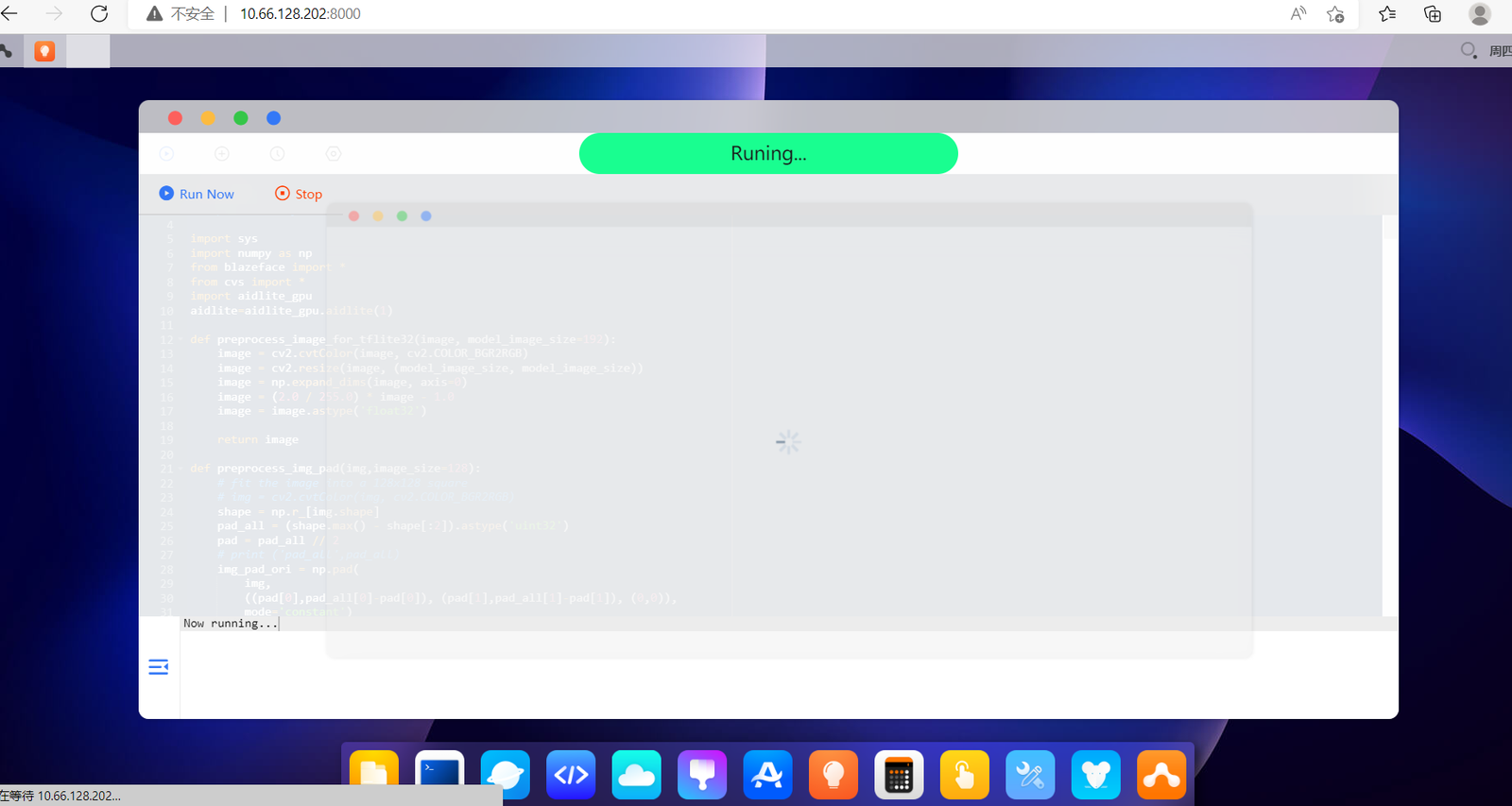
等待几秒钟,手机端就可以跳出人脸关键点的应用。
7.Android部署:Yolov5在AidLux中优化加速
在第六章节中,我们看到使用了csv和aidlite_gpu的库文件,那么为什么要用这些呢?
主要有两个原因:
(1)模型框架统一:PC端训练的框架有很多种,比如Tensorflow、Pytorch等,但是如果部署到安卓端,需要不同的适配,所以Aidlux中推出了基于Python的Aidlite API,对于各类AI框架的API进行了封装,便于使用。

因为AI框架也有很多,为了便于使用,平台端集成了十多种主流AI框架,比如TensorFlow、PyTorch、Caffe、MXNet、MNN、NCNN、MindSpore、PaddlePaddle、TNN、OpenCV,开箱可用。
(2)算力加速:大家也都知道,如果采用CPU跑AI项目的话,速度很慢,因此肯定要采用GPU算力,如果将前面的代码直接移植的话,主要跑的是CPU,检测速度比较慢。
当然我们手机当中也有芯片,所以Aidlux对于Android手机,实现了系统级智能加速,通过对于Python中的一些代码改造,即可调用推理加速的能力。
7.1 上传代码到AiLlux
我们首先打开手机版的aidlux,并投影到电脑网页上。然后第一步先将Yolov5的所有代码,上传到aidlux的平台里面。
点击电脑端页面菜单栏的第一个,文件浏览器,打开文件管理页面。
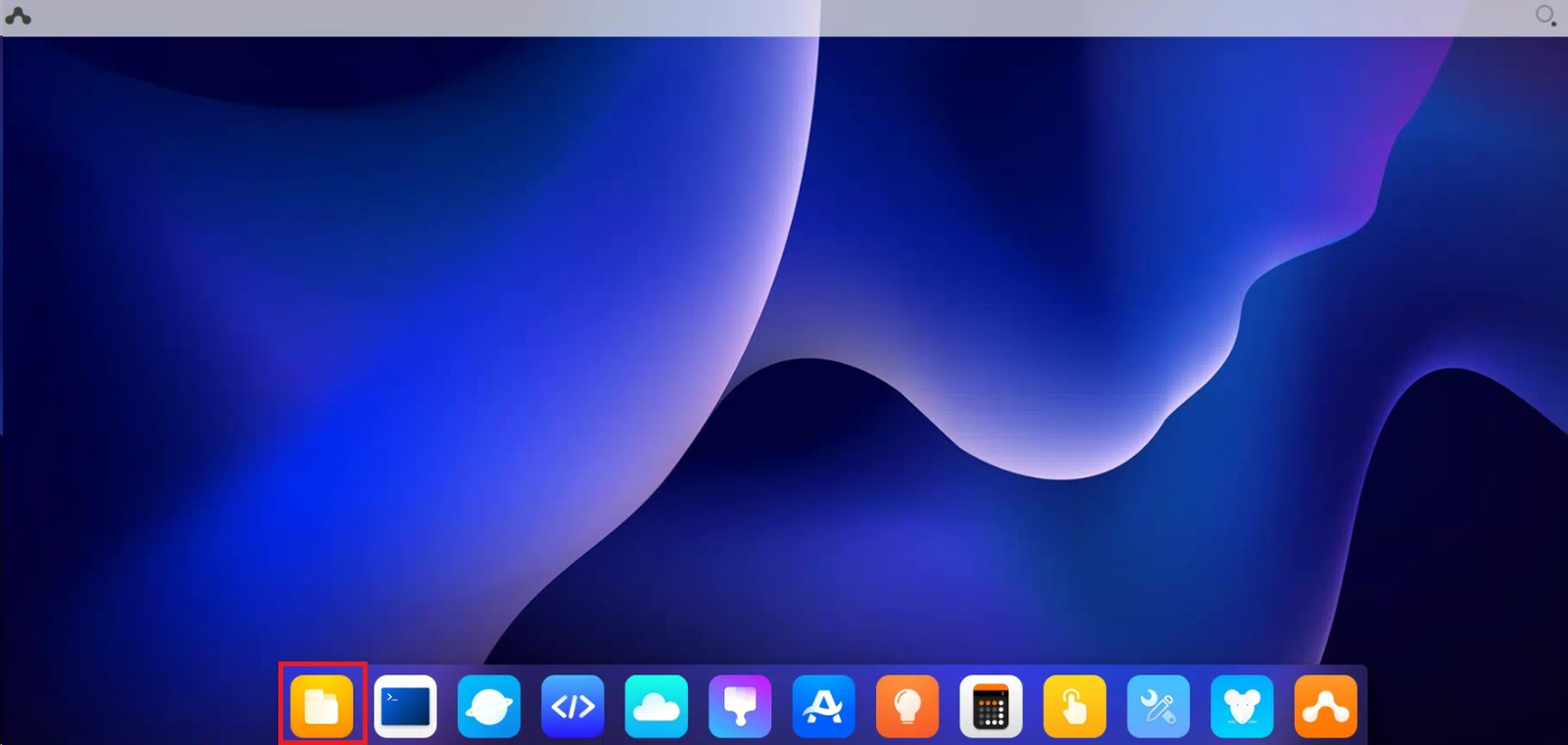
找到home文件夹,并双击进入此文件夹。
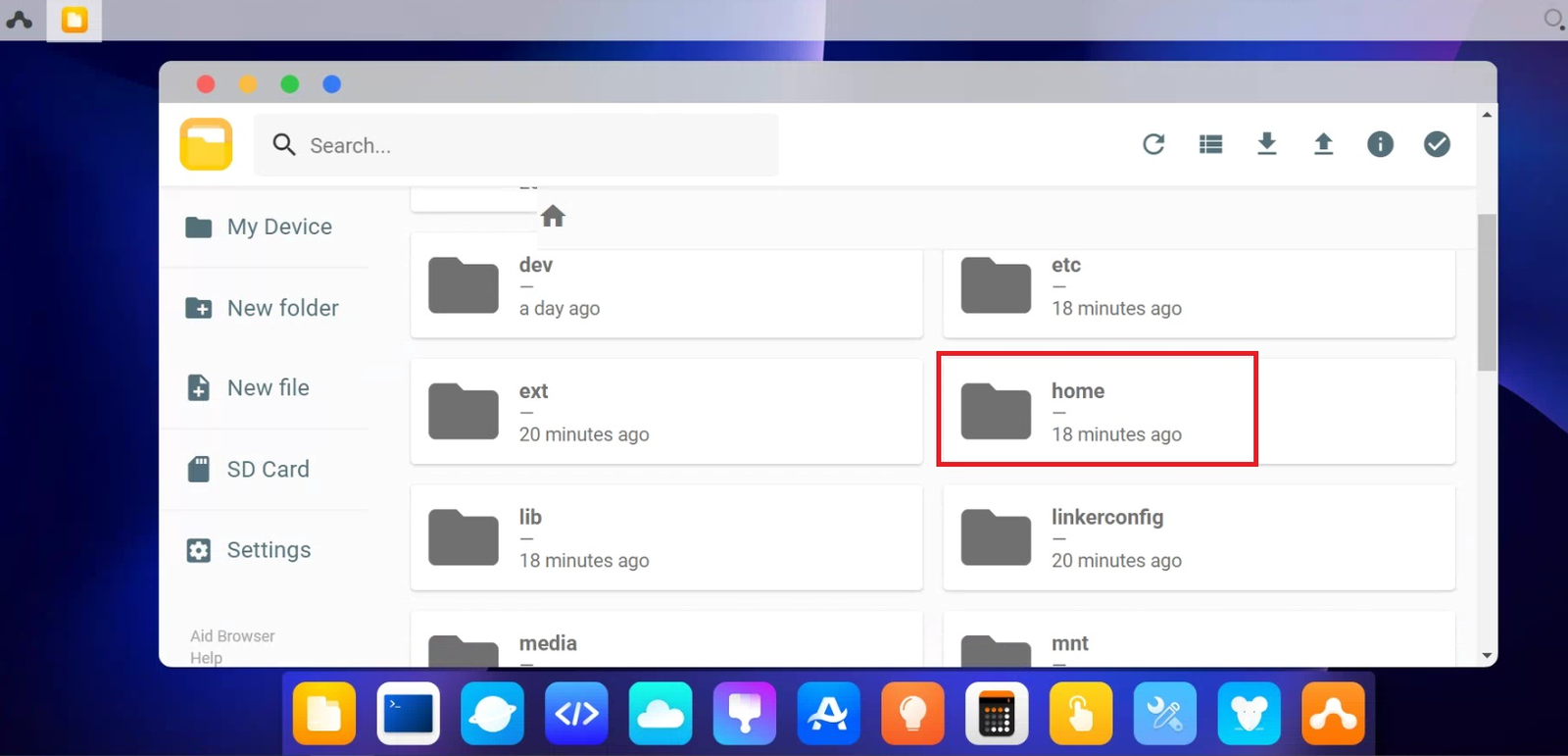
点击右上角往上的箭头“upload”,再选择Folder,将前面Yolov5的文件夹上传到home文件夹内。
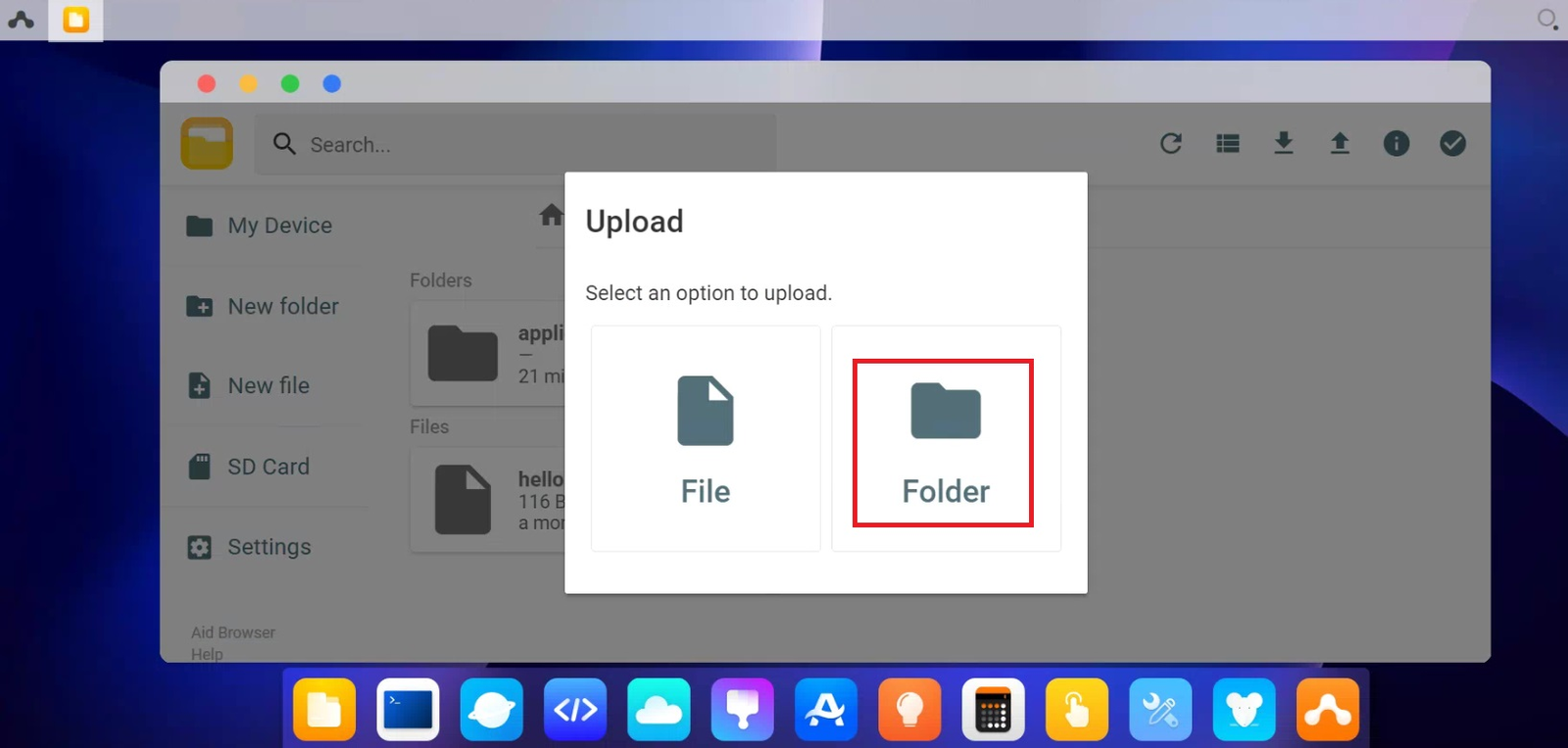
点击选择上传
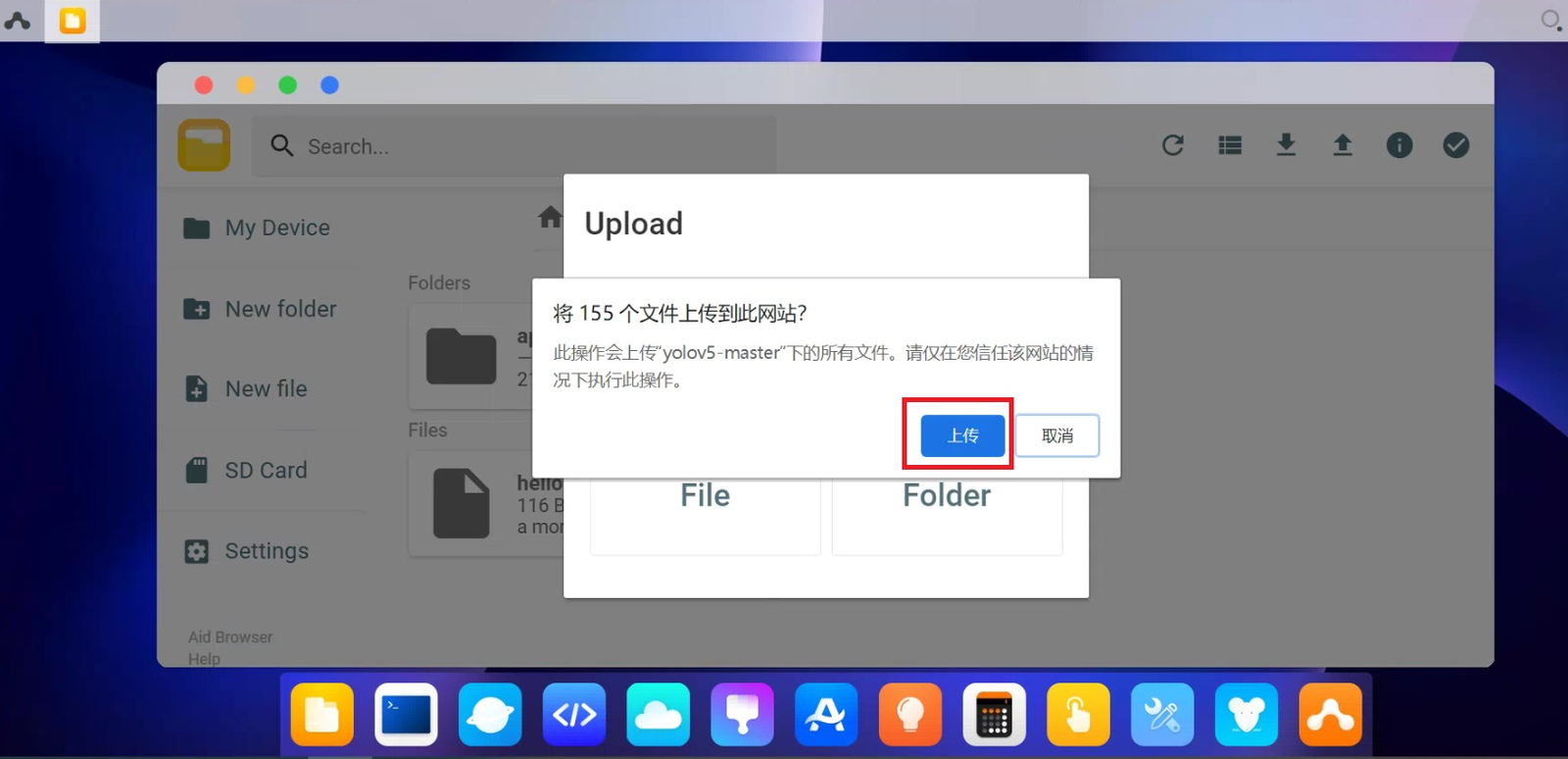
上传好后,在Yolov5的aidlux文件夹中,可以看到大白修改过的代码,主要对于yolov5的优化加速,以及七牛云、喵提醒的整合。

其中包含了三个文件,yolov5.py是主函数文件,utils.py是配置文件,yolov5s.tflite是模型转换后的文件,后面7.4节中,大白也会带着大家模型转换操作一遍。
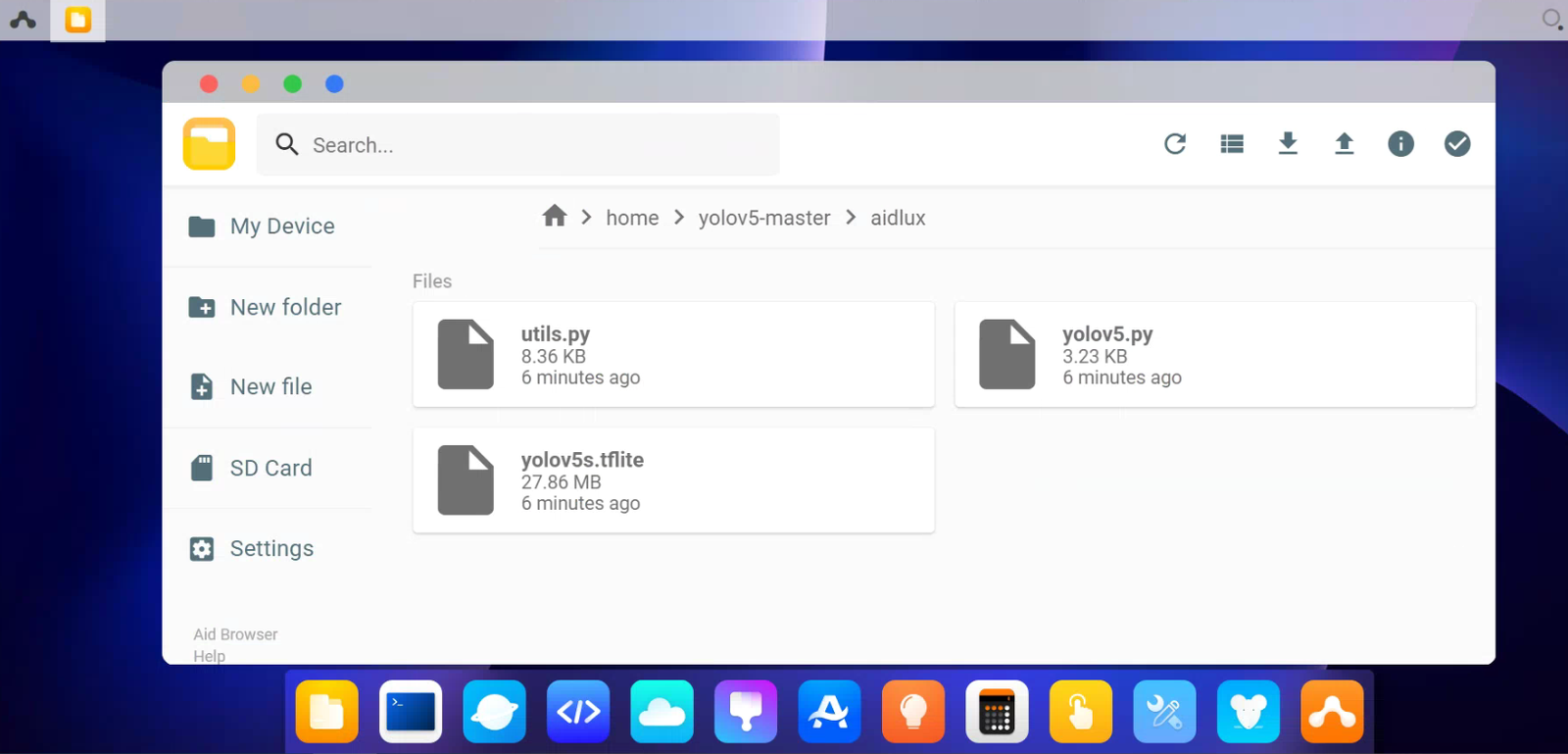
7.2 安装相应的依赖库 点击yolov5s.py文件后,我们可以看到其中包含aidlux的库文件,还有七牛云的一些库文件。因为七牛云的代码是新整合进来的,所以我们还需要下载一下所依赖的七牛云的库文件。 在桌面的空白栏,右击选择打开终端。
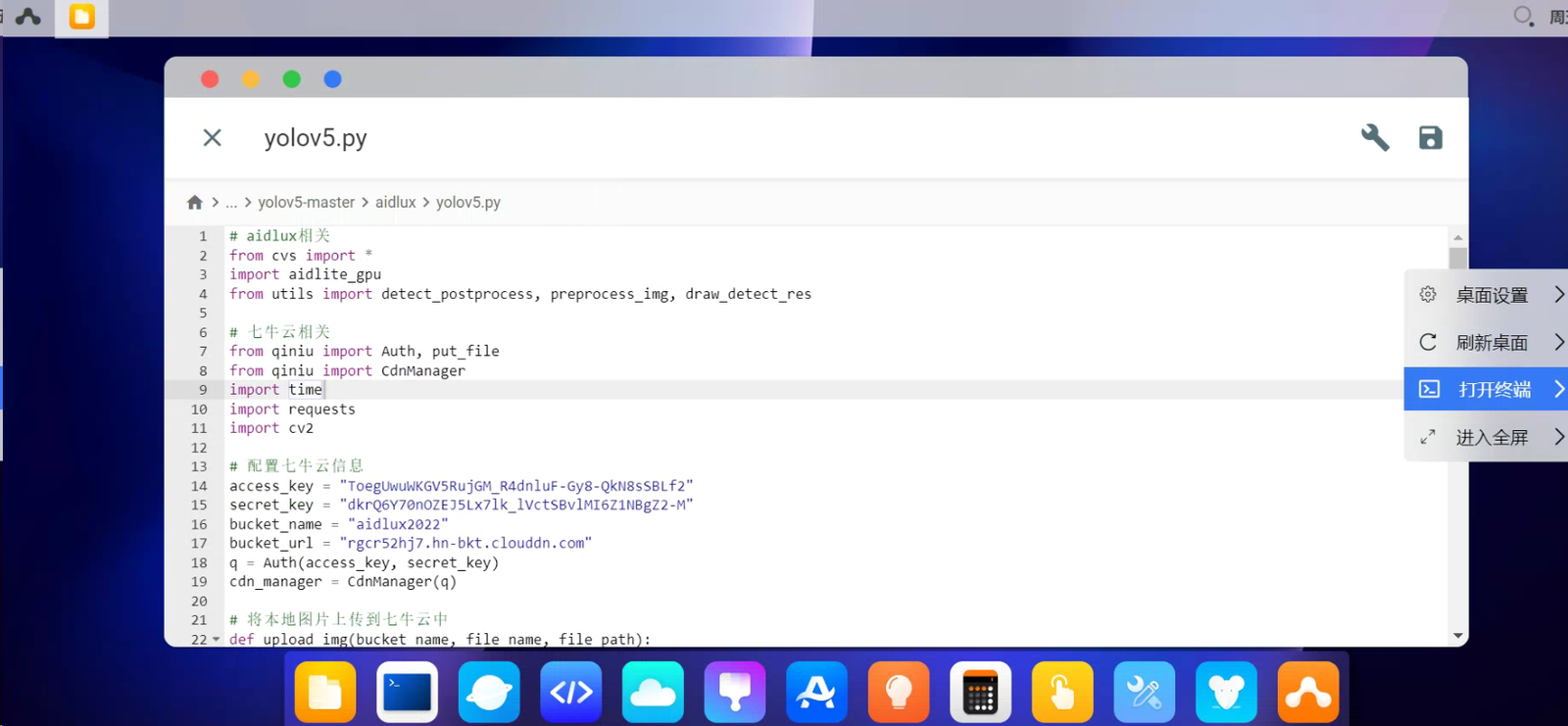
在代码输入部分,输入 pip3 install qiniu -i https://pypi.tuna.tsinghua.edu.cn/simple,即可快速下载成功。
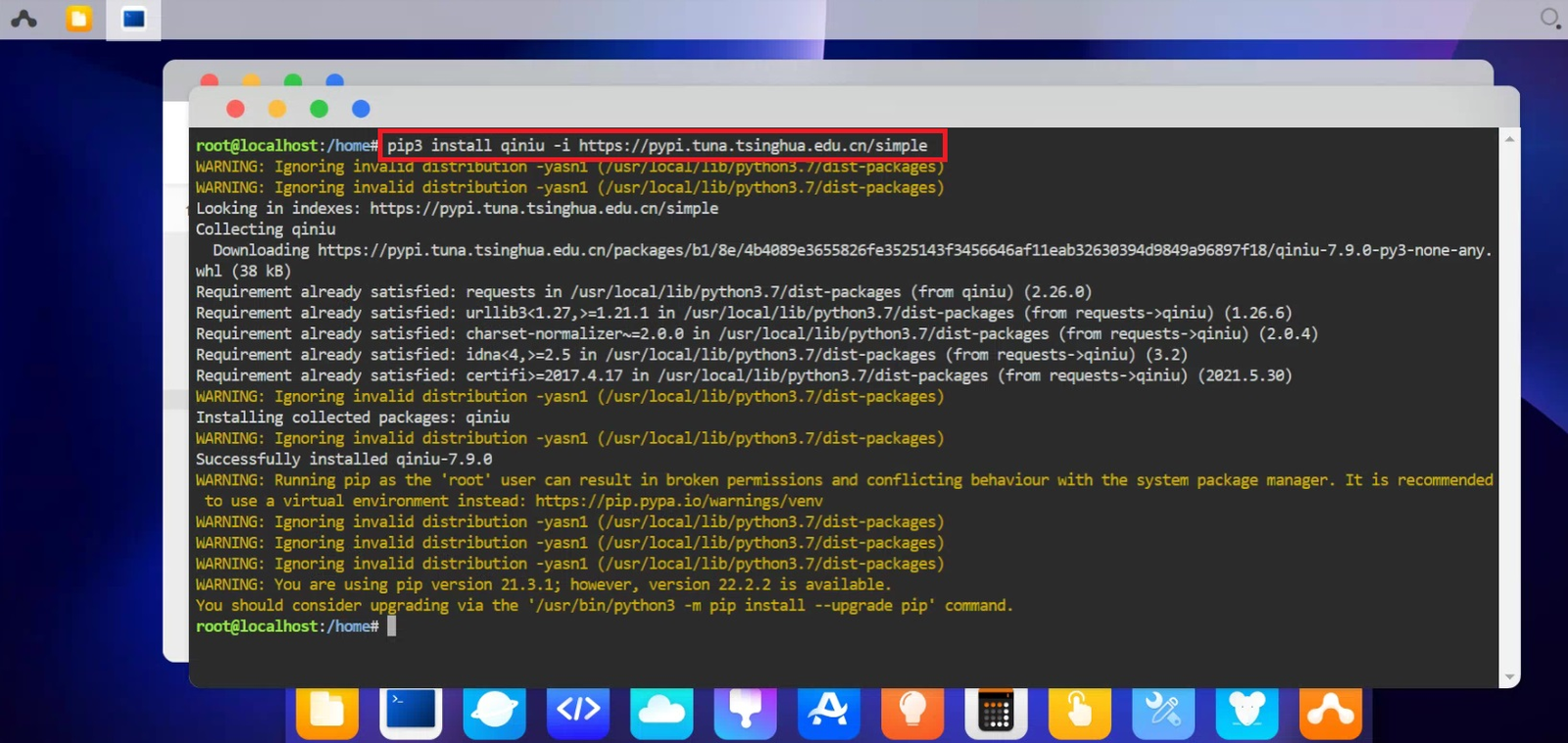
再输入python3,输入 import qiniu,没有报错,说明下载完成。

7.3 代码查看对比
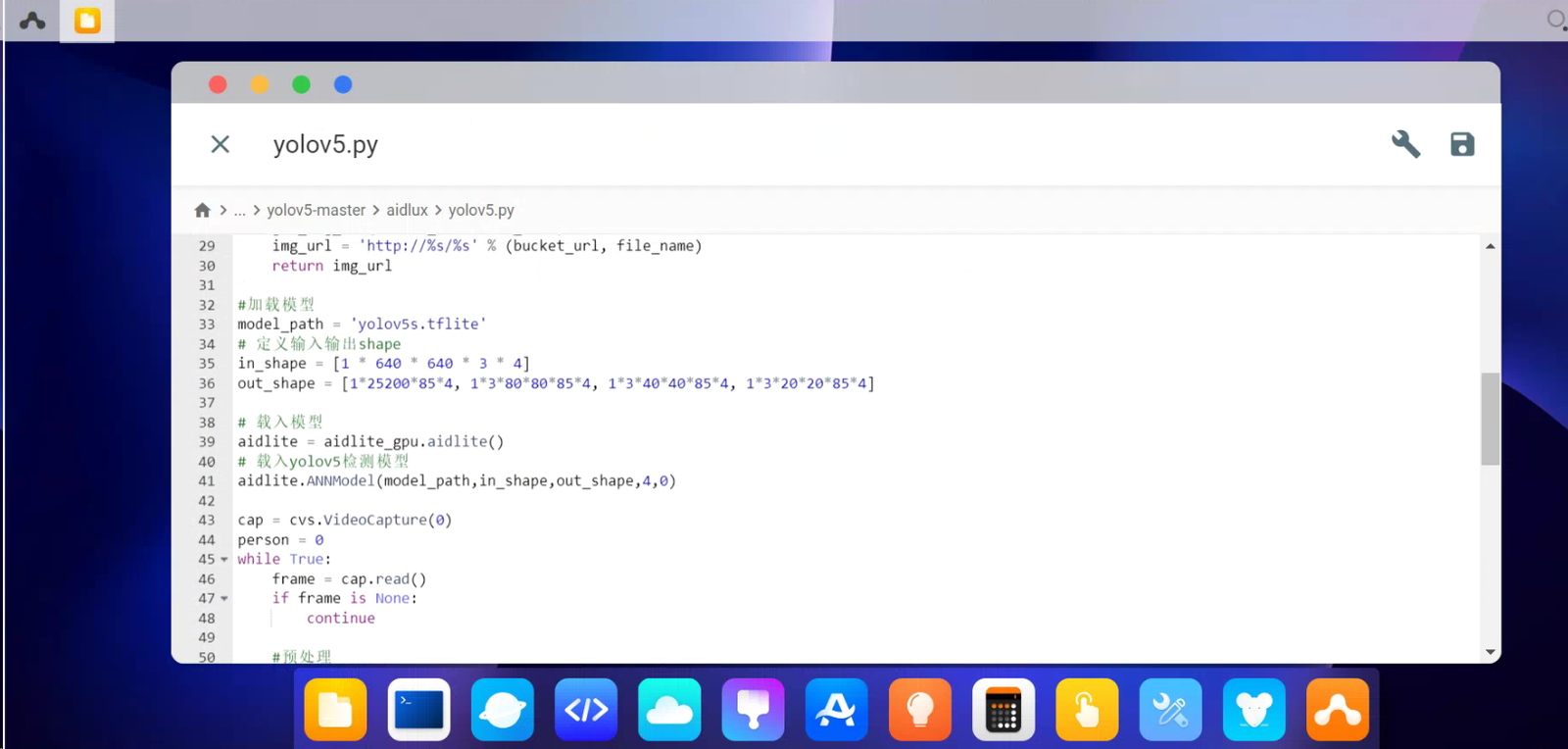
我们再来按照aidlux平台的优化加速代码,重新看下整合过的yolov5代码。
和PC端的Yolov5不同的地方在于,加载模型,载入模型,以及图片推理时的地方。
那么如果我们自己训练的模型,如何在aidlux进行转换部署呢?
7.4 自有模型移植部署
我们再以一个训练好的pt模型为例,演示一下整体的检测流程。
(1)pt模型转换
因为aidlux里面用的是tensorflow框架的tflite模型,所以我们先将训练好的pt模型转换成tflite模型。
先在PC端电脑上,打开yolov5的代码,找到export.py,主要修改两个地方。
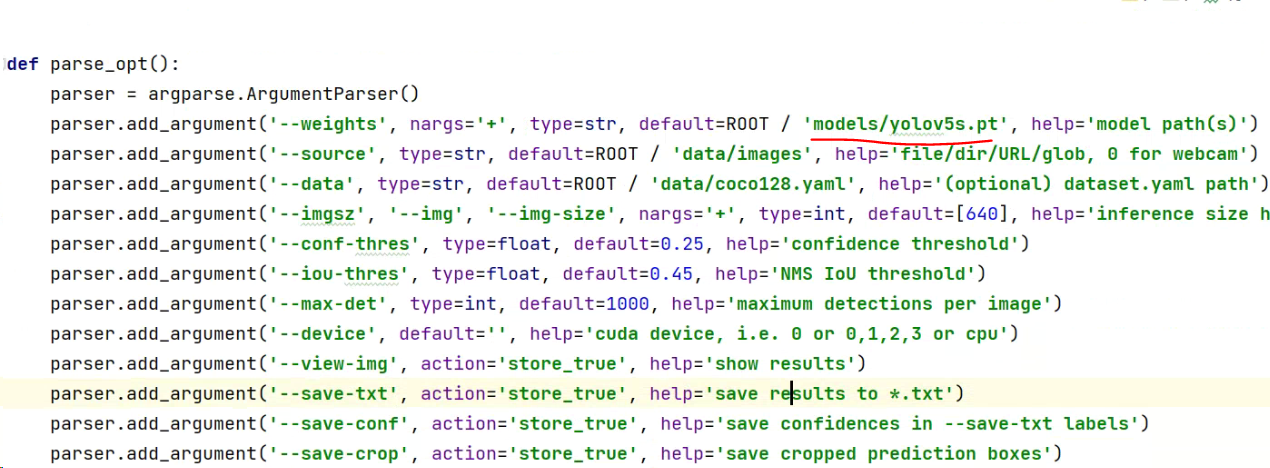
第一个是修改模型的路径,即weights的路径,修改export.py文件最下面的parse_opt配置函数。
因为yolov5的模型,放在models文件夹里面,所以将detault修改成“models/yolov5s.pt”。
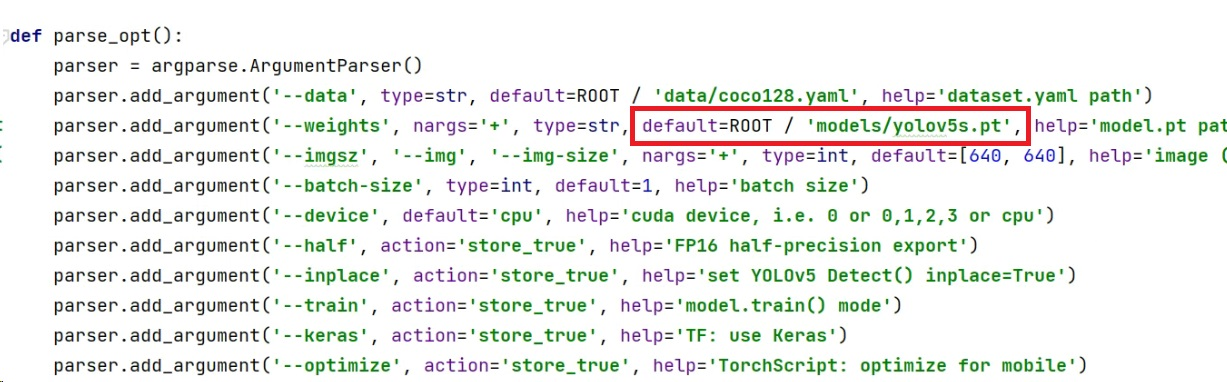
第二个是修改模型转换成的格式,将include的default修改成“tflite”。
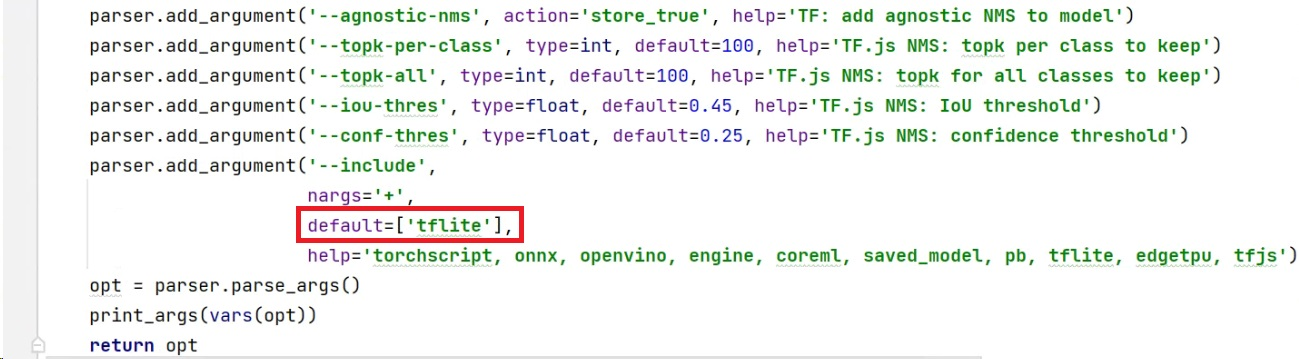
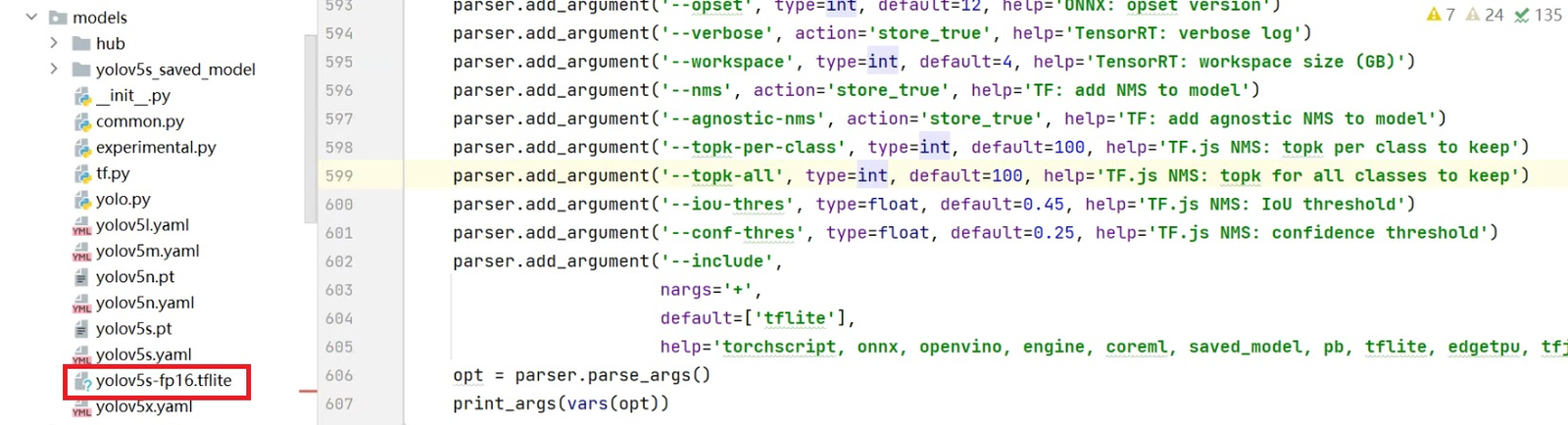
代码运行转换后,在models文件夹里面,可以看到转换后的yolov5s-fp16.tflite模型。
当然,在运行过程中,如果有提示缺少一些库文件的报错,可以自行安装一下。
接触过AI项目的同学也知道,模型权重的数值有float32、float16、int8,从float32->in8,模型精度略有下降的同时,可以带来推理速度的几倍提升。
大白这里主要采用的是中间float16的形式,如果在后面手机端推理,感觉速度比较慢,想加快模型推理速度的话,可以转换成int8的格式。
(2)查看模型参数
使用netron查看转换后的tflite模型的信息,可以直接登录netron的在线网站版本https://netron.app/。

选择open model,打开刚刚导出的yolov5s-fp16.tflite模型。
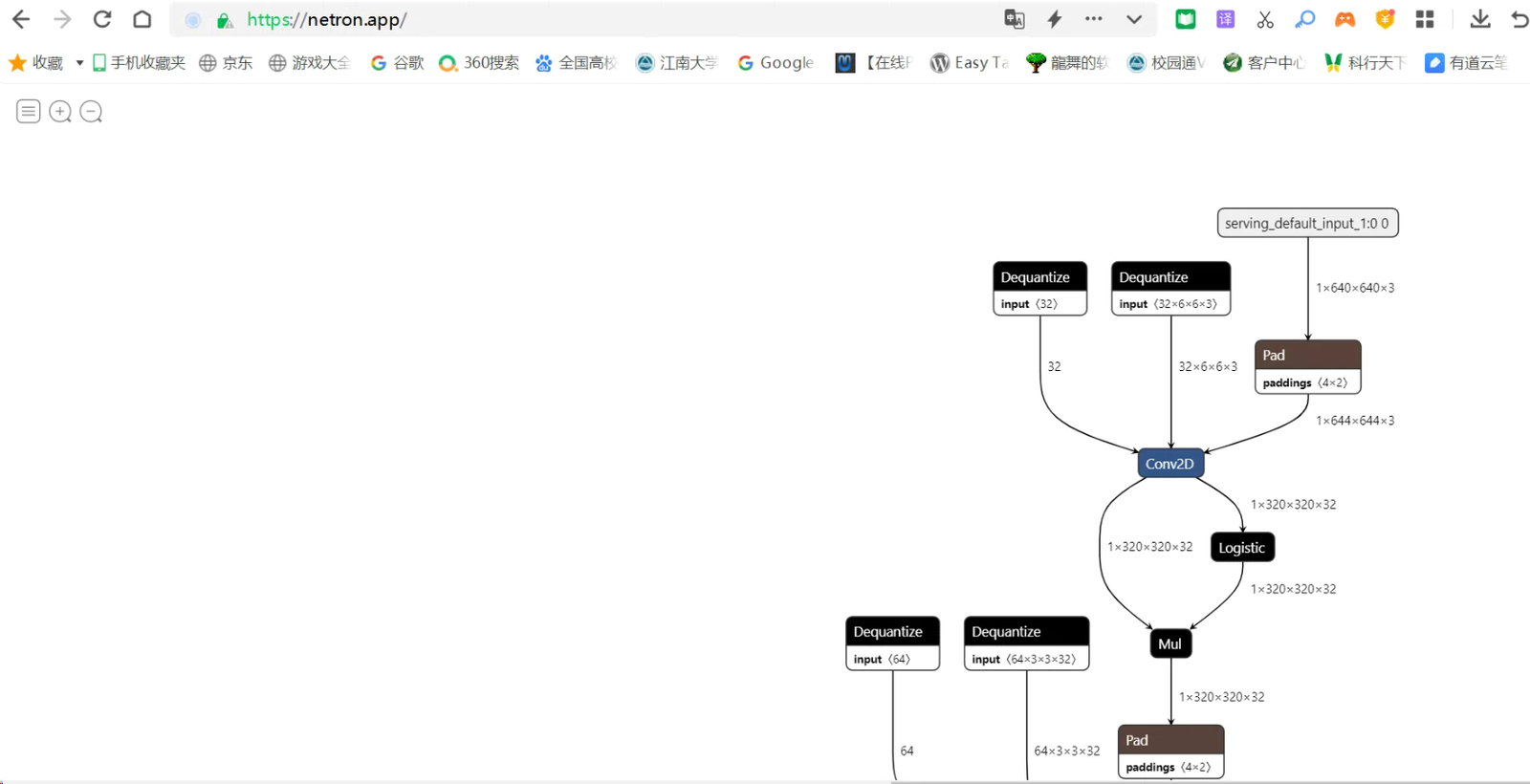
网页的滚动条一直拉到最下面,点击最后的一个模块,可以看到右面的弹窗,会跳出输入信息[1,640,640,3]和输出信息[1,25200,85]。
(3)修改代码中的信息
将导出的yolov5s-fp16.tflite,放到aidlux文件夹下面。
打开yolov5.py文件,主要修改模型的路径model_path,和输入输出信息。
yolov5文件中的pt模型是CoCo数据集训练出的模型,主要有80个类别,因此out_shape中有一个85,即1(前景背景概率)+4(检测框坐标信息)+80(类别信息)。
此外输入是640640大小,最后的三个特征图输出则是8080,4040,2020,如果大家调整类别和输入大小时,也要想要的修改,需要注意。

4)AidLux上传代码
打开Aidlux的页面,打开文件浏览器,进入yolov5-master的aidlux文件夹中,将修改后的yolov5.py和yolov5s-fp16.tflite进行替换。
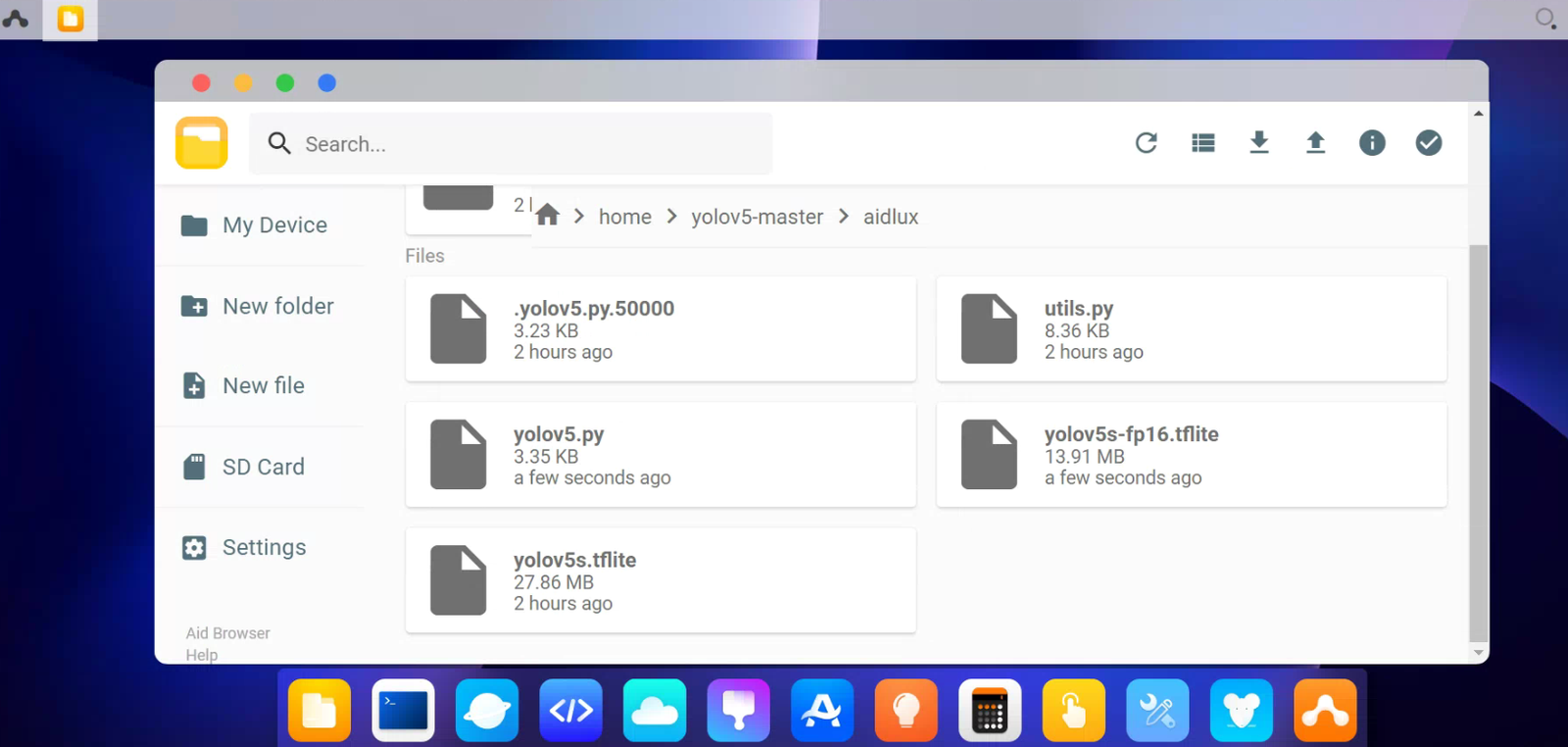
7.5 运行代码查看效果
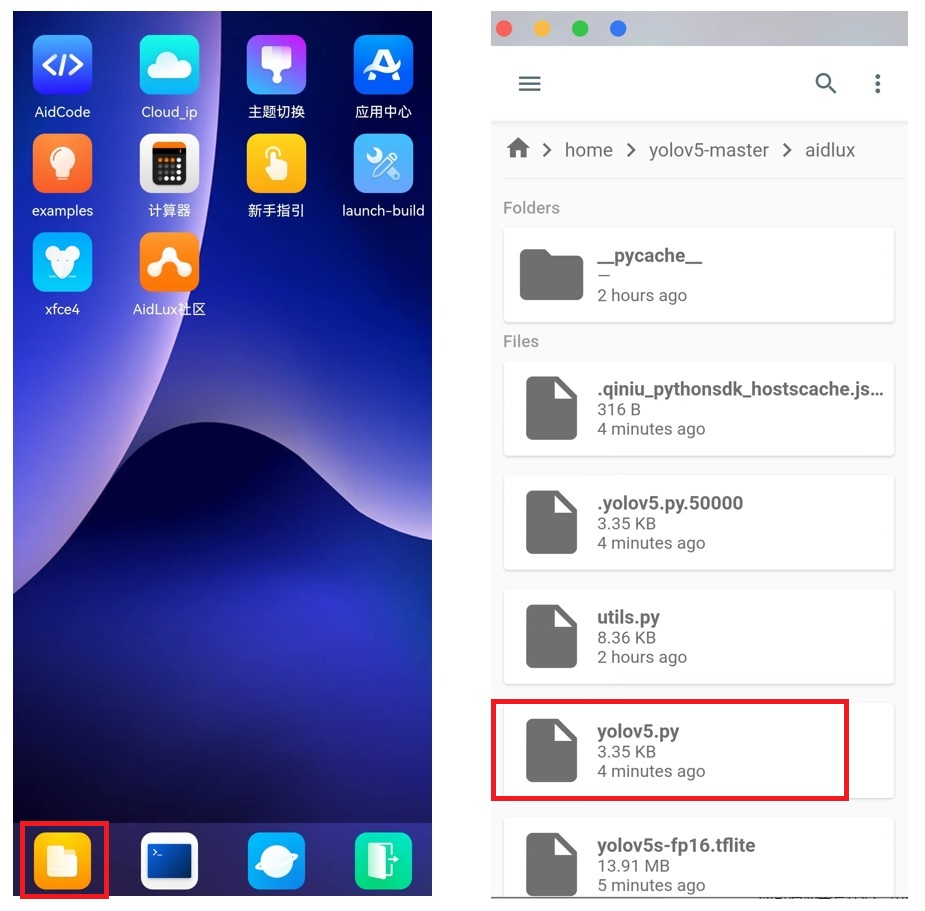
我们再来看一下修改后的代码的运行效果,不过这里最好直接采用手机端的aidlux来进行启动。
进入aidlux界面,找到文件浏览器,进入home/yolov5-master文件夹中,打开yolov5.py文件。
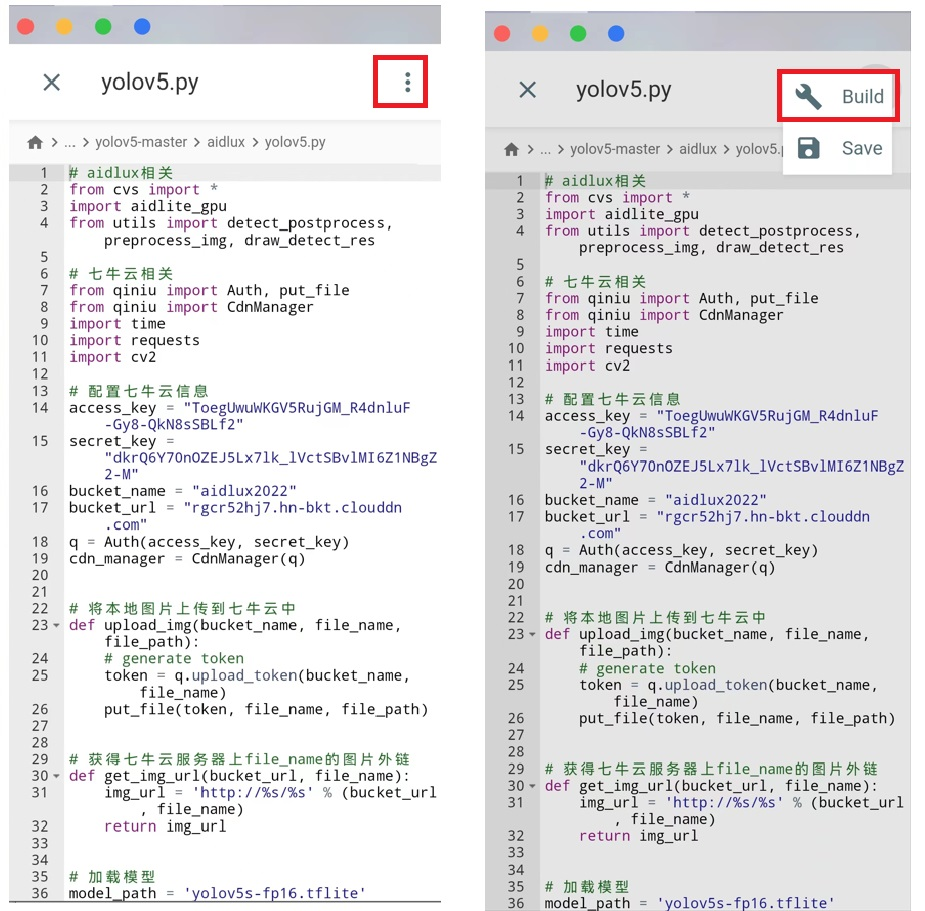
点击右上角的图标,选择“Build”。
进入代码的运行页面,选择左上角的坐标,点击“Run Now”。
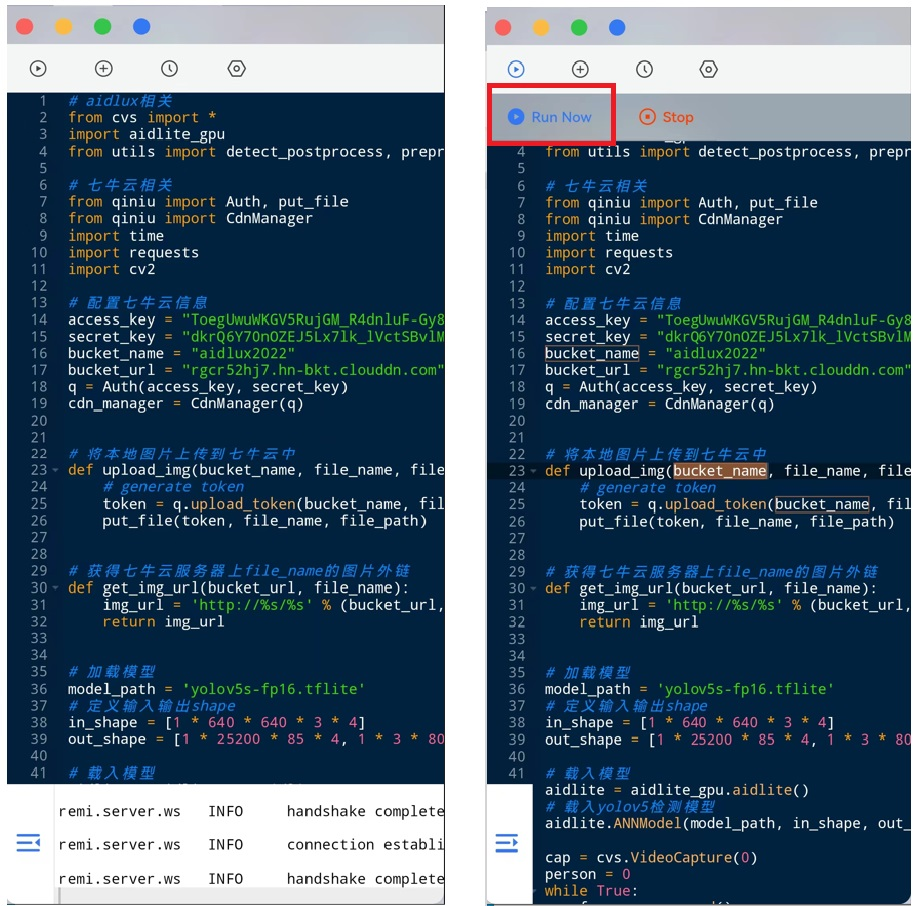
可启动整套代码,电脑端也能实时看到检测的画面。 当实际使用中,检测到入侵的人员时,手机上的喵提醒,即可收到提示的报警信息。

PS:如果大家打开这个二url链接,一直是同一张图片,说明微信中存在缓存,可以将此url链接复制,在手机任意一个浏览器中,以无痕模式打开即可。
8.延伸产品:家庭AI安防系统
8.1 AI相关产品应用
到了这里,按照一步步操作,我们可以实现一整套的安防监测产品了。
大家外出时,晚上游玩时,或者家里面店铺看守等,都可以使用这套安防监测产品,在家里放置一个手机监视即可。
当然除了安防监测,也可以发挥想象力,做很多其他的应用。
比如婴幼儿看护,在手机上做好应用后,使用手机支架,夹放在婴幼儿的围挡处,当画面中儿童不见时,自动告警提醒查看。
AI行业就有一家公司,专门做了一款这种婴幼儿防护产品,公司估值2个多亿,销售量也非常不错。
对AidLux感兴趣的同学,可以加入AidLux官方交流群,群内有官方工程师和AI行业的大神在线互动。
4、其他要求
应用作品文章需图文结合,并附带视频展示。
图文部分涉及到AidLux的环节和内容,需要有使用AidLux的图片展示;
文中需要插入展示项目效果的视频,在AidLux开发者社区发帖插入视频,需粘贴B站视频,可先将视频上传。
视频示例1:
视频示例2:
视频示例3:
视频示例4: