@TOC
0.前言
项目是之前做的,使用Windows训练,并使用Deep stream部署在Nvidia Jetson Xavier NX上,最近接触Aidlux,将这个项目移植过来。
1.模型训练
1.1 任务描述
任务是估算一个输电杆塔的旋转角度,我这里把不同角度的输电杆塔作为不同的标签,转化为图像识别问题。
1.2 输电杆塔数据集采集
采集数据集用的是一个输电杆塔的塑料模型,这种模型网上很多,一般是铁路沙盘会用到。
我没买电动的旋转台,就自己打印了一张纸,划分了一下刻度,然后旋转纸采集数据。为了保证数据多样性,采集的时候后面放了个显示器放电视剧,更换背景。
我大概采集了12个标签一共一千多张。

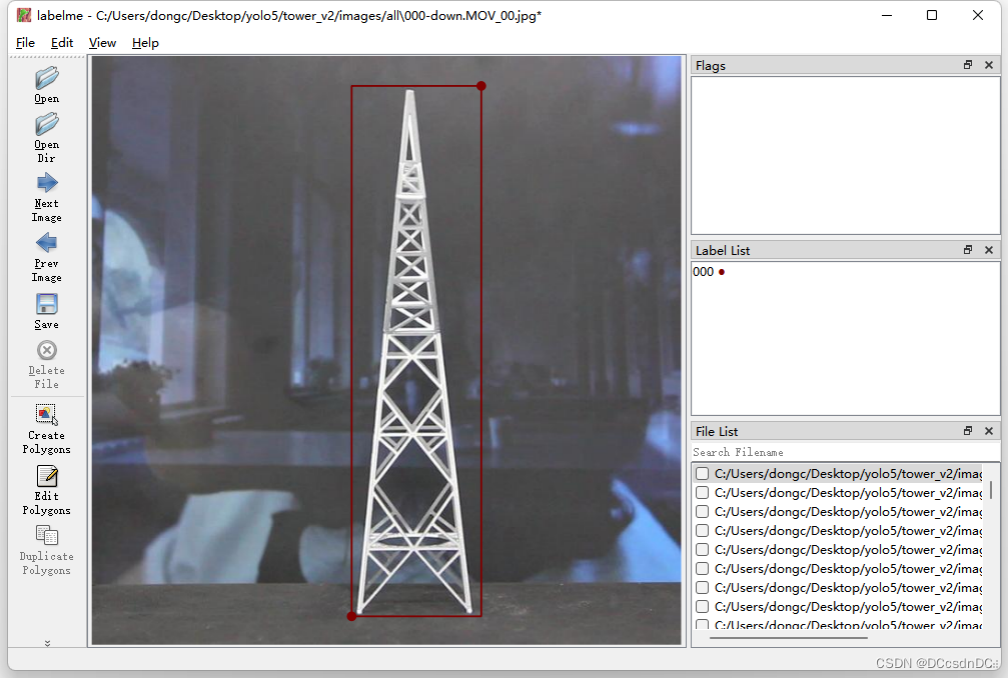
1.3 输电杆塔数据集标注
标注采用的是labelme软件,标注的结果是json格式,写个python脚本转成txt的。把图片和txt分成数据集和训练集存放,大致比例是8:2。
1.4 数据增强
YOLO v5 自带数据增强,这里注意我们是要判断角度,就不能使用镜像反转这种增强方法。同时,因为采集的时候塔的大小、位置都比较单一,因此缩放、平移这种增强就要多做。
1.5 折腾
YOLO自带了几个不一样的激活函数、IOU损失函数、NMS之类的,可以换一换,默认的就挺好用。
还有一种东西叫超参数进化,类似于自动调参,这东西极其消耗算力,我这一张2080ti要跑一个多月,想想算了。
1.6 训练
我这个数据集小,一共就训练了80轮,再多就容易过拟合了。训练的时候看好了损失函数,要是损失函数好久不下降了就要担心过拟合了。
1.7 测试
测试了一下没啥问题,复杂背景也识别的不错。

2.NX部署
2.1 软硬件
Jetson Xavier NX,配合Deep stream。默认系统一般是不带Deep stream的,需要自己用SDKmanager安装一下。这个安装比较麻烦,容易踩坑。
在这里推荐Github的CDR(cv-deepsream-robot)项目,在jetson上很好用。
2.2 Tensor RT 优化推理
这个不多说了,教程很多。注意的是,优化推理的时候从FP32到FP16是可以直接量化的,但是到INT8精度损失太大了,需要做一个校准,校准需要很多数据集,我这里做出来效果不好,用的是FP16。
FP32 大概是83fps,FP16是130fps。
2.3 ROS Topic发送
这里感谢CDR的ROS代码和XTDrone的Gazebo无人机环境。
3.Aidlux部署
3.1 介绍
Aidlux的个人版可以直接在小米应用商店安装,如果应用商店没有也可以直接参考Aidlux官方文档
安装之后会有一个权限设置过程,按照APP提示一步步操作即可。

安装好的Aidlux自带了几个例程,可以直接运行。

Aidlux支持局域网访问,点击桌面上的Cloud_ip即可获得一串网址,在局域网内任意浏览器输入即可打开远程开发界面。

3.2 环境配置
在Adilux的应用商店直接一键安装conda。
之后把电脑上的YOLO工程文件夹直接复制到Adlux的home文件夹下。
或者也可以直接git YOLO源码
git clone https://github.com/ultralytics/yolov5.git
有一些环境需要安装,一般来说他报错什么直接pip install就行,但是cv2不行,需要安装指定版本。
``` sudo pip3 install --no-cache-dir opencv-contrib-python==3.4.17.61pip install torchvision
pip install pandas
pip install Pillow
pip install pyyaml
pip install tqdm
pip install matplotlib
pip install seaborn
<p>之后运行detect.py,即可看到检测结果。</p>
<pre><code class="language-python"># YOLOv5 ? by Ultralytics, GPL-3.0 license
"""
Run inference on images, videos, directories, streams, etc.
Usage - sources:
$ python path/to/detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
Usage - formats:
$ python path/to/detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s.xml # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (MacOS-only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
"""
import argparse
import os
import sys
from pathlib import Path
import cv2
import torch
import torch.backends.cudnn as cudnn
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import DetectMultiBackend
from utils.datasets import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams
from utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr,
increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh)
from utils.plots import Annotator, colors, save_one_box
from utils.torch_utils import select_device, time_sync
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
@torch.no_grad()
def run(weights=ROOT / 'yolov5s.pt', # model.pt path(s)
source=ROOT / 'data/images', # file/dir/URL/glob, 0 for webcam
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project=ROOT / 'runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
):
source = str(source)
save_img = not nosave and not source.endswith('.txt') # save inference images
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
webcam = source.isnumeric() or source.endswith('.txt') or (is_url and not is_file)
if is_url and is_file:
source = check_file(source) # download
# Directories
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(imgsz, s=stride) # check image size
# Dataloader
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt)
bs = len(dataset) # batch_size
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt)
bs = 1 # batch_size
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
model.warmup(imgsz=(1 if pt else bs, 3, *imgsz)) # warmup
dt, seen = [0.0, 0.0, 0.0], 0
for path, im, im0s, vid_cap, s in dataset:
t1 = time_sync()
im = torch.from_numpy(im).to(device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
t2 = time_sync()
dt[0] += t2 - t1
# Inference
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(im, augment=augment, visualize=visualize)
t3 = time_sync()
dt[1] += t3 - t2
# NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
dt[2] += time_sync() - t3
# Second-stage classifier (optional)
# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
annotator.box_label(xyxy, label, color=colors(c, True))
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
# Stream results
im0 = annotator.result()
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path[i] != save_path: # new video
vid_path[i] = save_path
if isinstance(vid_writer[i], cv2.VideoWriter):
vid_writer[i].release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer[i].write(im0)
# Print time (inference-only)
LOGGER.info(f'{s}Done. ({t3 - t2:.3f}s)')
# Print results
t = tuple(x / seen * 1E3 for x in dt) # speeds per image
LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
if update:
strip_optimizer(weights) # update model (to fix SourceChangeWarning)
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'best.pt', help='model path(s)')
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--data', type=str, default=ROOT / 'data/tower_v2.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.1, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.2, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(FILE.stem, opt)
return opt
def main(opt):
check_requirements(exclude=('tensorboard', 'thop'))
run(**vars(opt))
if __name__ == "__main__":
opt = parse_opt()
main(opt)
</code></pre>
<p>这里检测的是本机的图片</p>
<p><img src="https://img-blog.csdnimg.cn/996ba2bc497a403e86eca1b9b0f221ce.png" alt="在这里插入图片描述" /></p>
<p>这里对比了用CPU和GPU的方法,可以看到CPU大概0.5fps,GPU大约6~7fps</p>
<p>GPU</p>
<p><img src="https://aidlux.oss-cn-beijing.aliyuncs.com/imgs/微信截图_202212081841379479061623502242801670496641732976596.png" alt="" /><img src="https://aidlux.oss-cn-beijing.aliyuncs.com/imgs/微信截图_2022120818433990722675951081188541670496639367347381.png" alt="" /></p>
<p>CPU</p>
<p><img src="https://aidlux.oss-cn-beijing.aliyuncs.com/imgs/微信截图_2022120818433949382454931427679031670496655584826584.png" alt="" /></p>
<p><a href="https://www.bilibili.com/video/BV1s44y1S7t2/?vd_source=5896b1818b29c8956651abd2ccdf821f">使用Aidlux运行YOLO V5 检测输电杆塔_哔哩哔哩_bilibili</a></p>
<p>这是GPU代码</p>
<pre><code class="language-python">
from cvs import *
import aidlite_gpu
from utils import detect_postprocess, preprocess_img, draw_detect_res
#加载模型
model_path = 'best.tflite'
in_shape = [1 * 640 * 640 * 3 * 4, ]
out_shape = [1*25200*17*4, 1*3*80*80*17*4, 1*3*40*40*17*4, 1*3*20*20*17*4]
aidlite = aidlite_gpu.aidlite()
aidlite.ANNModel(model_path,in_shape,out_shape,4,0)
cap = cvs.VideoCapture(0)
while True:
frame = cap.read()
if frame is None:
continue
#预处理
img = preprocess_img(frame, target_shape=(640, 640), div_num=255, means=None,stds=None)
aidlite.setInput_Float32(img,640,640)
#推理
aidlite.invoke()
pred = aidlite.getOutput_Float32(0)
pred = pred.reshape(1,25200,17)[0]
pred = detect_postprocess(pred, frame.shape, [640, 640, 3], conf_thres=0.5,iou_thres=0.45)
res_img = draw_detect_res(frame, pred)
cvs.imshow(res_img)
</code></pre>