
背景:
起源于Rocky老师的AidLux训练营,
课程共计6节课,首先分享的是第5节“车辆检测&AI安全算法实现流程”
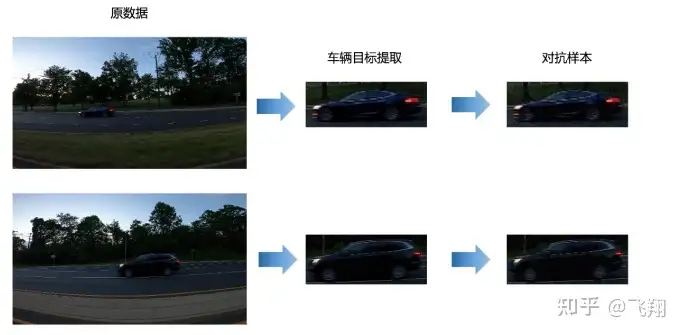
在第三节课中,我们学习了用目标检测YOLOv5算法训练一个车辆检测模型,并进行了基于数据为中心 的鲁棒性优化。 在第四节课中,我们又进行了对抗攻击与对抗防御的尝试,了解攻击者的手段和防御者的防御策略。 了解了智慧交通场景下,攻击者可能使用的手段后,就可以更好的做各种防御者的预防工作了。 熟悉了检测算法流程和AI攻防策略,接下来我们将二者结合,就可以进行AI安全项目的学习研究了。 经过前面章节的学习,我们知道在智慧交通的很多场景中,检测任务是整个任务逻辑的首要环节,比 如车牌检测识别,交通事件识别,行人车辆级联任务等。 而AI安全风险多发于算法解决方案中,前后任务的关键级联点中。 比如当我们检测出车辆时,后续要进行车牌检测识别,车辆属性识别,车型识别以及车标识别等级联 任务。 这时如果攻击者将干净的车辆框替换成含对抗扰动的对抗样本,可能导致后续任务出现误判,比如原 本是一辆卡车,需要判断是否超载,但是出现误判,变成了一辆小轿车了,从而导致严重的安全风 险。
所分享的是:将结合车辆检测+AI安全+分类模型的模式,将攻击与防御注入到检测任务与分类任务的级联点 中,完成AI项目的对抗攻防安全功能。
1.AI安全项目功能讲解
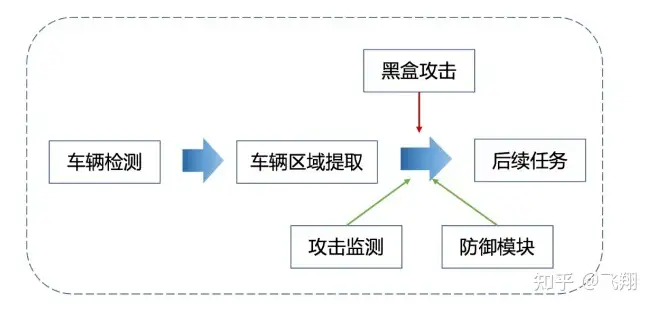
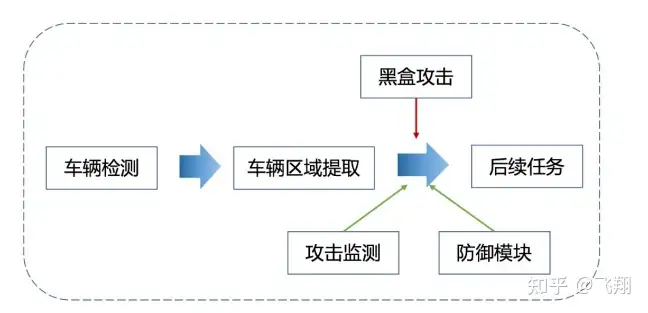
我们提取车辆目标的区域,可以进行后续的车牌识别,车型识别,车标识别,驾驶员行 为识别等后续级联算法功能。 而AI安全风险也往往会在两个任务级联的关键路径中出现,比如当提取车辆目标区域时,针对小轿车 有一套分析逻辑,针对大卡车有一套分析逻辑,但是因为被攻击的原因,导致分析逻辑出现错乱,就 有问题了。
尝试使用黑盒攻击对项目的关键路径进行攻击,这也更加贴合实际应用,因为 在真实场景下,我们并不知道对方使用了什么模型,所以只能进行黑盒攻击。 我们主要使用基于迁移生成的对抗样本,对车辆检测模型后续的级联分类模型进行黑盒攻 击。
面对黑盒攻击,我们一 起注入相应的黑盒防御策略,进行安全风险的抵御。 我们在YOLOv5模型与分类模型中增加一个对抗风险监测模型,当检测到AI安全风险时,返回告警信息 和告警图片。 一般在实际应用的项目业务系统中,会出现一个告警弹窗。 比如某个图片被识别为对抗样本,出现告警信息,便会安排人员进行及时评估。 这时候,数据流会被切断,后续级联任务暂时停止,在评估好安全风险后,我们可以选择对这张图片 进行对抗噪声破坏操作或者直接在算法流程中移除。
为了更加贴近实际,在本训练营中,我们才用了一种更加简单实 用的方式,即通过微信“喵提醒”的方式。
2 车辆检测区域目标提取
我们先进行第一步,从图片中将车辆相关的小图检测,并扣取出来,做后续的分析。
2.1 代码复制到Aidlux
和之前的Aidlux的使用说明和详细操作实例一样,我们将Lesson5_code的代码,全部上传到Aidlux的home下面。
还是在网页版的Aidlux中,打开文件浏览器,进入home下方,点击上传按钮,将Lesson5_code文件夹进行上传。
https://www.bilibili.com/video/BV1m24y1k7rn/
在第三节课,我们完成了车辆检测模型的训练与优化,在实际智慧城市的AI项目中,包括车辆检测在内的检测任务往往是第一道工序,后续会级联如车牌识别,车型识别,车标识别,驾驶员行为识别等细分任务。
因此,我们需要将车辆区域提取,输入到后续的任务流中。

2.2 Aidlux端车辆目标区域提取保存
我们依然使用SSH连接到Aidlux的方式。大家也可以远程连接到Lesson5_code,当看到VScode左下角部分的SSH:AIDLUX呈现绿色,即说明远程连接成功。
在本章节中,我们使用一个函数来提取车辆目标区域,并将其保存至yolov5_code/aidlux/extract_results文件夹中。函数代码在yolov5_code/aidlux/utils.py中。
def extract_detect_res(img, all_boxes, image_name):
'''
检测结果提取
'''
img = img.astype(np.uint8)
color_step = int(255/len(all_boxes))
for bi in range(len(all_boxes)):
if len(all_boxes[bi]) == 0:
continue
count = 0
for box in all_boxes[bi]:
x, y, w, h = [int(t) for t in box[:4]]
#cv2.putText(img, f'{coco_class[bi]}', (x, y), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
#cv2.rectangle(img, (x,y), (x+w, y+h),(0, bi*color_step, 255-bi*color_step),thickness = 2)
cut_img = img[y:(y+h), x:(x + w)]
cv2.imwrite("yolov5_code/aidlux/extract_results/" + image_name + "_" + str(count) + ".jpg",cut_img)
count += 1
其中车辆目标区域的保存路径需要进行修改。
接着我们修改yolov5_code/aidlux/yolov5_extract.py文件,主要是两个路径需要修改:
# aidlux相关 from cvs import * import aidlite_gpu from utils import detect_postprocess, preprocess_img, draw_detect_res, extract_detect_resimport time
import cv2AidLite初始化:调用AidLite进行AI模型的加载与推理,需导入aidlite
aidlite = aidlite_gpu.aidlite()
Aidlite模型路径
model_path = ‘yolov5_code/models/yolov5_car_best-fp16.tflite’
定义输入输出shape
in_shape = [1 * 640 * 640 * 3 * 4]
out_shape = [1 * 25200 * 6 * 4]加载Aidlite检测模型:支持tflite, tnn, mnn, ms, nb格式的模型加载
aidlite.ANNModel(model_path, in_shape, out_shape, 4, 0)
读取图片进行推理
设置测试集路径
source = "yolov5_code/data/images/tests"
images_list = os.listdir(source)
print(images_list)
frame_id = 0读取数据集
for image_name in images_list:
frame_id += 1
print("frame_id:", frame_id)
image_path = os.path.join(source, image_name)
frame = cvs.imread(image_path)# 预处理 img = preprocess_img(frame, target_shape=(640, 640), div_num=255, means=None, stds=None) # 数据转换:因为setTensor_Fp32()需要的是float32类型的数据,所以送入的input的数据需为float32,大多数的开发者都会忘记将图像的数据类型转换为float32 aidlite.setInput_Float32(img, 640, 640) # 模型推理API aidlite.invoke() # 读取返回的结果 pred = aidlite.getOutput_Float32(0) # 数据维度转换 pred = pred.reshape(1, 25200, 6)[0] # 模型推理后处理 pred = detect_postprocess(pred, frame.shape, [640, 640, 3], conf_thres=0.25, iou_thres=0.45) # 绘制推理结果 res_img = draw_detect_res(frame, pred) # cvs.imshow(res_img) # 测试结果展示停顿 #time.sleep(5)
我们再理解一下模型推理,车辆目标提取代码:
# 图片裁剪,提取车辆目标区域 extract_detect_res(frame, pred, image_name)# cvs.imshow(cut_img) # cap.release() # cv2.destroyAllWindows()
比起第三章的模型推理测试代码,这里我们增加了一个extract_detect_res函数来实现目标区域提取与保存。
接着我们运行yolov5_extract.py,可以看到如下log:
等代码运行结束,我们进入Lesson5_code/yolov5_code/aidlux/extract_results文件夹中,可以看到所有车辆目标提取图片。
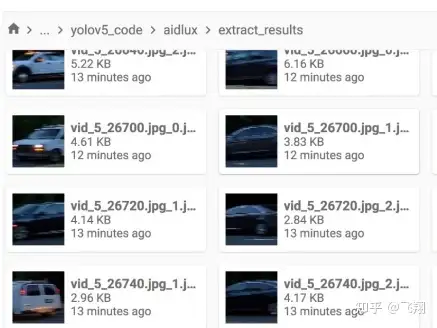
3 Aidlux端注入黑盒攻击样本
有了车辆区域后,就可以模拟真实的场景,模拟外部用户对模型进行攻击,使得模型识别的能力出现错乱。
经过前面课程的学习,我们已经知道对抗攻击分为白盒攻击与黑盒攻击,在第四章的时候,我们学习了白盒攻击与白盒防御的相关知识。
在本节课中,我们在使用白盒攻击的基础上,进行迁移攻击,形成基于迁移的黑盒攻击。
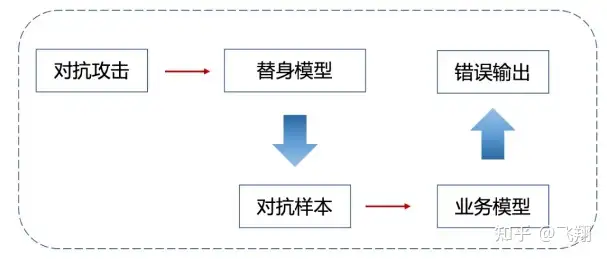
具体来说,上面我们已经将车辆目标区域提取出来,在实际AI项目中,攻击者一般难以获得算法模型的参数,白盒攻击难以展开。
这时,可以选择另外一个模型作为替身模型,比如我们知道他后面会进行车辆分类,但是不知道用的什么分类模型(实际上系统方用的Mobilenetv2),这时我们可以使用一个已有的分类模型(ResNet18)作为替身。
使用攻击算法对替身模型进行攻击,这样生成的车辆目标区域对抗样本一定程度上也会使得业务模型产生错误的输出。
3.1 PC端代码理解
针对迁移攻击的代码,Rocky放在Lesson5_code/adv_code/black_attack.py中了。
接下来我们一起理解一下具体代码细节。
(一)数据读取
首先我们进行数据的读取,我们需要修改的是img_path路径,在Lesson5_code/adv_code/orig_images中包含了一些已经提取的车辆目标图,大家可以进行迁移攻击,可以直观的看到效果。
### 读取图片 def get_image(): img_path = os.path.join("adv_code/orig_images", "vid_5_31560.jpg_0.jpg") img_url = "https://farm1.static.flickr.com/230/524562325_fb0a11d1e1.jpg"def _load_image(): from skimage.io import imread return imread(img_path) / 255. if os.path.exists(img_path): return _load_image() else: import urllib urllib.request.urlretrieve(img_url, img_path) return _load_image()
(二)加载常规模型和替身模型
这里我们将Mobilenetv2作为常规模型,将ResNet18作为替身模型。
为什么加载两种模型呢?
在业务场景下,客户系统用Mobilenetv2,把扣取出的车的小图,识别成了出租车,这是正确的。
而替身模型,是攻击者自己掌握的模型,进行攻击后,生成新的攻击样本(比如在图片上增加了非常不起眼的扰动),这时再用常规模型Mobilenetv2,去进行分类识别时,看是否识别就错误了,比如识别成卡车、或者救护车了。
当攻击者掌握了以上的漏洞后,他在一些业务场景,增加这种不起眼的干扰因素,客户系统就会出现各种问题。
同样的,这次实验我们选择了Pytorch已经训练好的预训练模型ResNet18,运行代码时,会将相应的预训练权重下载下来。
如果出现下载有问题的情况,dont’t worry 我们也可以选择本地Rocky已经下载好的模型权重,在Lesson5_code/model/resnet18-5c106cde.pth中。
### 常规模型加载 model = mobilenet_v2(pretrained=True) model.eval() model = nn.Sequential(normalize, model) model = model.to(device)替身模型加载
model_su = resnet18(pretrained=True)
model_su.eval()
model_su = nn.Sequential(normalize, model_su)
model_su = model_su.to(device)
(三)生成具备迁移攻击性的对抗样本
在这里,我们全部使用替身模型ResNet18的相关信息进行对抗样本的生成,比如替身模型的参数,输出label。
我们还是使用PGD攻击算法,各参数和上一节课保持一致。除了使用PGD对抗攻击算法外,大家还可以使用其他的算法进行尝试,Rocky将在后面的小节中给出一些示例供大家参考。
(四)测试黑盒攻击的效果
对抗样本生成以后,我们用常规模型MobileNetv2进行测试。

我们可以看到,MobileNetv2将两个出租车识别成为了雄孔雀和牵引车。
(五)迁移攻击样本保存
我们将生成的对抗样本保存在Lesson5_code/adv_code/adv_results中,可以看到,Rocky已经生成了一些对抗样本,大家可以方便地进行测试。
### 迁移攻击样本保存
save_path = "adv_code/adv_results/"
torchvision.utils.save_image(advimg.cpu().data, save_path + "adv_image.png")
3.2 PC端黑盒攻击样本效果验证
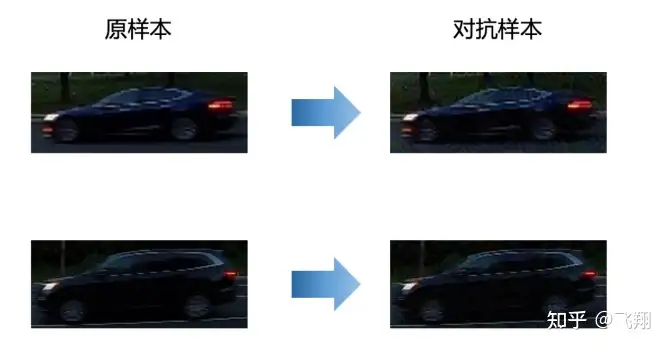
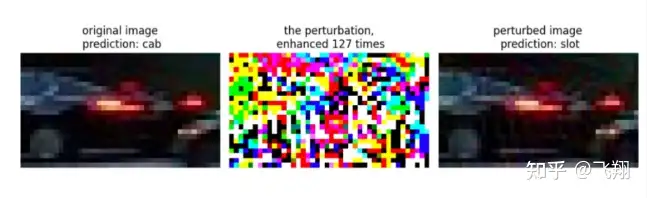
我们运行Lesson5_code/adv_code/black_attack.py代码,可以看到,虽然攻击的是ResNet18模型,但是对抗样本依然能够影响MobileNetv2,使其输出错误类别。
比如下面一辆车,原本是cab出租车,但是增加扰动攻击后,就被识别成购物运输的马车了。

比如下面一辆车,原本也是cab出租车,但是增加扰动攻击后,就被识别成购物运输的slot了。
4 Aidlux端项目注入黑盒防御策略
面对上面讲到的实际场景中可能存在的黑盒攻击,我们就需要提前准备,设计相应的黑盒防御策略。
在业务系统中,可以通过防御策略,比如通过二分类模型(正常图片和扰动图片),告知工作人员,图像中可能出现安全风险,这样系统就更加安全了。
那么有哪些黑盒防御策略呢?
具体来说,黑盒防御策略主要有数据预处理,设计鲁棒性模型结构,使用对抗样本监测模型等方法。
方法有很多,不过为了大家快速掌握,主要使用对抗样本监测模型的形式。
4.1 对抗攻击监测模型理解
在前面的学习中,我们知道,对抗攻击监测模型是一个能够捕捉对抗扰动的二分类模型,监测模型的输入是一张图片,输出则是两个类别,0表示图片是正常图片,1表示图片是具有安全风险的图片。
本次训练营中,Rocky直接使用了一个已经训练好的基于ResNet50的模型,作为本次训练营的监测模型。
在实际场景中,当数据流中的图片进入AI项目中时,在一些关键节点处,可以前置一个监测模型,用于判断输入数据是否存在安全风险,如果发现对抗样本,则及时告警,并切断后续的算法功能,避免不确定风险的产生。
比如在智慧交通场景中,对每一个车辆进行提取,再进入对抗攻击监督模型判断是正常的图片,还是具有安全风险的图片。
比如在智慧交通场景中,对每一个车辆进行提取,再进入对抗攻击监督模型判断是正常的图片,还是具有安全风险的图片。
本课程中的监测模型代码如下所示:
### 对抗攻击监测模型 class Detect_Model(nn.Module): def __init__(self, num_classes=2): super(Detect_Model, self).__init__() self.num_classes = num_classes #model = create_model('mobilenetv3_large_075', pretrained=False, num_classes=num_classes) model = create_model('resnet50', pretrained=False, num_classes=num_classes)# self.multi_PreProcess = multi_PreProcess() pth_path = os.path.join("model", 'track2_resnet50_ANT_best_albation1_64_checkpoint.pth') #pth_path = os.path.join("/Users/rocky/Desktop/训练营/Lesson5_code/model/", "track2_tf_mobilenetv3_large_075_64_checkpoint.pth") state_dict = torch.load(pth_path, map_location='cpu') is_strict = False if 'model' in state_dict.keys(): model.load_state_dict(state_dict['model'], strict=is_strict) else: model.load_state_dict(state_dict, strict=is_strict) normalize = NormalizeByChannelMeanStd( mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # self.model = nn.Sequential(normalize, self.multi_PreProcess, model) self.model = nn.Sequential(normalize, model) def load_params(self): pass def forward(self, x): # x = x[:,:,32:193,32:193] # x = F.interpolate(x, size=(224,224), mode="bilinear", align_corners=True) # x = self.multi_PreProcess.forward(x) out = self.model(x) if self.num_classes == 2: out = out.softmax(1) #return out[:,1:] return out[:,1:]
4.2 系统告警
当对抗攻击监测模型,监测到对抗样本或者对抗攻击后。
一般在实际场景的AI项目中,会出现一个告警弹窗,并且会告知安全人员及时进行安全排查。
当然我们此次训练营并没有业务系统,为了更加贴近实际,本次训练营采用一种简单的方式,当然也比较实用,即通过微信“喵提醒”的方式来实现。在后面的大作业中,我们也会使用到。
(一)新建喵提醒账号
首先关注“喵提醒”公众号,点击回复消息中最后的“注册账号”,填写手机号码进行注册,注册后跳到后台页面可以看到,今天还能收到提醒100条信息,基本上是够用的。
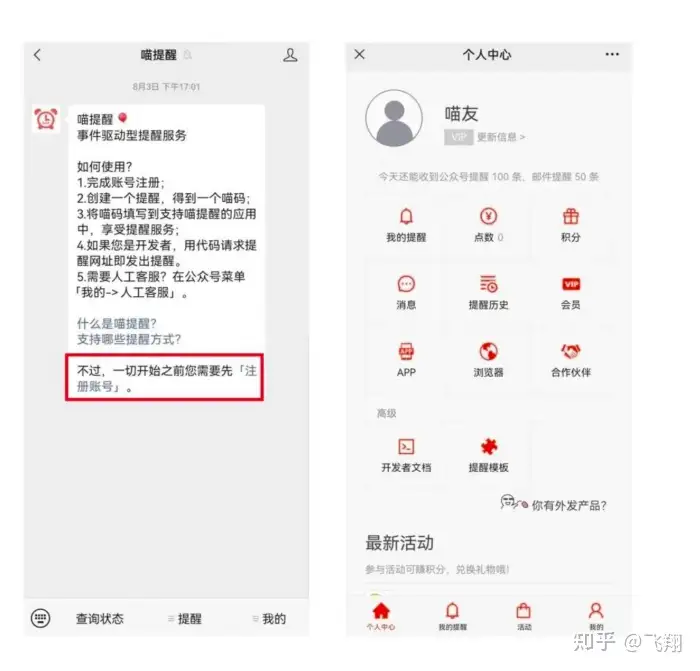
注册完成后,回到公众号页面,点击菜单栏的“提醒”,并选择新建。
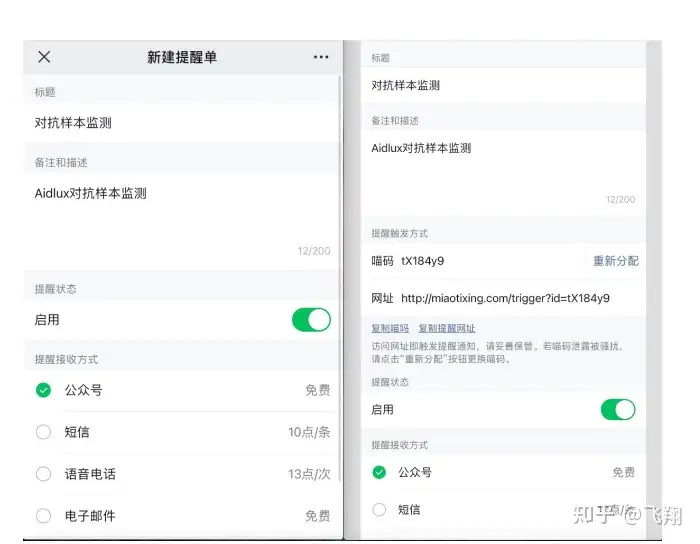
然后我们填写新建提醒的相关信息,点击最后的“保存”,页面会自动加载,中间的部分会自动跳出自己账号专属的“喵码”和“网站”,后面的代码中,我们主要使用“喵码”进行告警的反馈。
(二)喵提醒代码测试
为了测试喵提醒的效果,大家可以运行Lesson5_code/adv_code/miaotixing.py。
import requests import time填写对应的喵码
id = ‘tX184y9’
填写喵提醒中,发送的消息,这里放上前面提到的图片外链
text = "出现对抗攻击风险!!"
ts = str(time.time()) # 时间戳
type = ‘json’ # 返回内容格式
request_url = "http://miaotixing.com/trigger?"headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47’}
result = requests.post(request_url + "id=" + id + "&text=" + text + "&ts=" + ts + "&type=" + type,
headers=headers)
不过需要注意的是,代码中的id要改成自己的“喵码”,不然喵提醒信息会发送到我这边。
另外,text信息需要修改成告警信息,Rocky这里修改成“出现对抗攻击风险”的信息,大家也可以改成其他告警信息。
运行代码后,我们的手机上会收到一条告警信息。
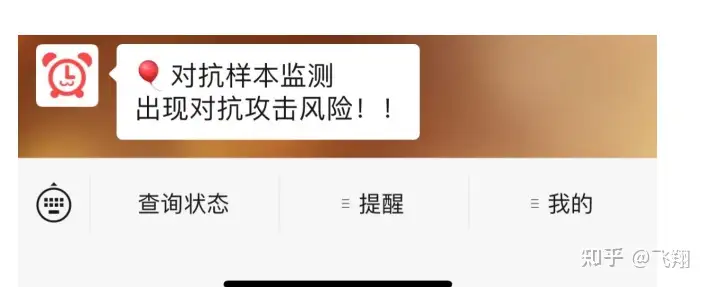
(三)对抗攻击监测 + 喵提醒
首先,我们需要修改对抗样本读取的路径img_path:
def get_image(): # img_path = os.path.join("adv_code/adv_results", "Cars28.png") img_path = os.path.join("adv_code/adv_results", "adv_image.png")img_url = "https://farm1.static.flickr.com/230/524562325_fb0a11d1e1.jpg" def _load_image(): from skimage.io import imread return imread(img_path) / 255. if os.path.exists(img_path): return _load_image() else: import urllib urllib.request.urlretrieve(img_url, img_path) return _load_image()
接着我们进行级联分类模型的配置,我们依然使用class的形式:
### 常规模型加载 class Model(nn.Module): def __init__(self, l=290): super(Model, self).__init__()self.l = l self.gcm = GradientConcealment() #model = resnet18(pretrained=True) model = mobilenet_v2(pretrained=True) # pth_path = "/Users/rocky/Desktop/训练营/model/mobilenet_v2-b0353104.pth" # print(f'Loading pth from {pth_path}') # state_dict = torch.load(pth_path, map_location='cpu') # is_strict = False # if 'model' in state_dict.keys(): # model.load_state_dict(state_dict['model'], strict=is_strict) # else: # model.load_state_dict(state_dict, strict=is_strict) normalize = NormalizeByChannelMeanStd( mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) self.model = nn.Sequential(normalize, model) def load_params(self): pass def forward(self, x): #x = self.gcm(x) #x = ResizedPaddingLayer(self.l)(x) out = self.model(x) return out
最后,我们设计告警逻辑,我们将输入后续级联任务模型的图片先经过对抗攻击模型网络。
如果被识别为对抗样本,那么使用喵提醒逻辑进行告警,如果被识别为干净样本,则开启后续级联任务的正常流程。
### 对抗攻击监测 detect_pred = detect_model(img) print(detect_pred)if detect_pred > 0.5:
id = ‘tCOWTW1’
# 填写喵提醒中,发送的消息,这里放上前面提到的图片外链
text = "出现对抗攻击风险!!"
ts = str(time.time()) # 时间戳
type = ‘json’ # 返回内容格式
request_url = "http://miaotixing.com/trigger?"headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'} result = requests.post(request_url + "id=" + id + "&text=" + text + "&ts=" + ts + "&type=" + type, headers=headers)
else:
pred = imagenet_label2classname(predict_from_logits(model(img)))
print(pred)
(四)对抗攻击监测 + 喵提醒效果验证
我们还是像之前一样,在aidlux平台上修改上面讲过的参数,运行代码。当我们选择Lesson5_code/adv_code/adv_results中对抗样本作为输入,可以看到微信上会反馈安全风险告警。
当我们选择Lesson5_code/adv_code/orig_images干净样本作为输入,可以看到顺利进行后续级联任务的流程。
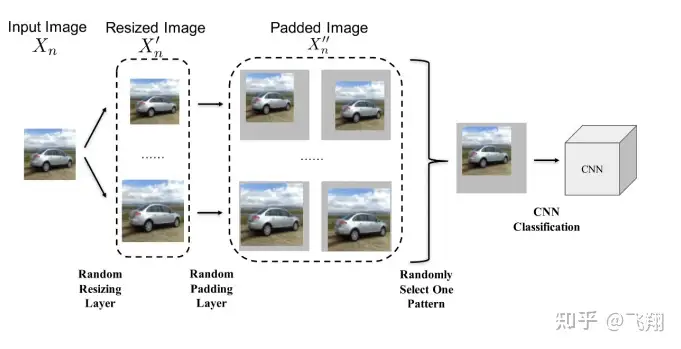
4.3 破坏对抗噪声的预处理模块
除了上面讲到的对抗攻击监测模块以外,我们也可以在 AI项目预处理阶段加入能提高模型鲁棒性的防御策略。
在预处理阶段的对抗防御策略中,对图像进行随机裁剪缩放和增加白噪声都能破坏对抗噪声结构,从而减弱对抗样本的威胁。
增加噪声破坏对抗噪声结构的方法主要是通过对输入图像添加微小的白噪声,使得对抗样本中本身就十分微小的对抗扰动结构破坏,从而一定程度上消除对抗扰动带来的影响。
下图主要使用对图像进行随机裁剪缩放的策略,来增强对扰动不明显的对抗样本的防御效果。
5 实战训练营大作业讲解及完成方式
到这里,本次训练营就要进入尾声了,通过这五节课,我们主要学习了智慧交通与AI安全的相关知识,训练优化了车辆检测模型,并尝试应用了对抗攻击与对抗防御的策略,最后完成了检测功能+AI安全功能+后续级联功能的智慧交通AI算法解决方案。
5.1 作业流程
大作业的目的,是使用车辆检测结果+对抗样本生成+对抗防御策略,完成AI安全风险预警的业务功能。
完成作业的整个流程,主要分为两个部分:
5.1.1 代码实现
(1)生成对抗样本
第一步先模拟攻击者,生成可以使得业务系统中,车辆分类识别会出现问题的对抗样本。
那么如何评判对抗样本的生成是有效果的呢?
这时就需要用到前面4.1中的监督模型ResNet50的模型,针对一张图片,会输出两个类别,正常图片0,有风险的图片1,从而判断我们生成的对抗样本是否有效果。
比如左面的车辆小图,原本是cab出租车,经过对抗攻击,生成右面的图片后,再输入ResNet50模型后,如果输出0,则表示对抗样本输出的不成功,没有生成具有安全风险的图片。

这里用到的数据,可以从Lesson5_code/adv_code/orig_images中选择。
# aidlux相关 from cvs import * import aidlite_gpu from utils import detect_postprocess, preprocess_img, draw_detect_res, extract_detect_resimport time
import cv2AidLite初始化:调用AidLite进行AI模型的加载与推理,需导入aidlite
aidlite = aidlite_gpu.aidlite()
Aidlite模型路径
model_path = ‘yolov5_code/models/yolov5_car_best-fp16.tflite’
定义输入输出shape
in_shape = [1 * 640 * 640 * 3 * 4]
out_shape = [1 * 25200 * 6 * 4]加载Aidlite检测模型:支持tflite, tnn, mnn, ms, nb格式的模型加载
aidlite.ANNModel(model_path, in_shape, out_shape, 4, 0)
读取图片进行推理
设置测试集路径
source = "yolov5_code/data/images/tests"
images_list = os.listdir(source)
print(images_list)
frame_id = 0读取数据集
for image_name in images_list:
frame_id += 1
print("frame_id:", frame_id)
image_path = os.path.join(source, image_name)
frame = cvs.imread(image_path)# 预处理 img = preprocess_img(frame, target_shape=(640, 640), div_num=255, means=None, stds=None) # 数据转换:因为setTensor_Fp32()需要的是float32类型的数据,所以送入的input的数据需为float32,大多数的开发者都会忘记将图像的数据类型转换为float32 aidlite.setInput_Float32(img, 640, 640) # 模型推理API aidlite.invoke() # 读取返回的结果 pred = aidlite.getOutput_Float32(0) # 数据维度转换 pred = pred.reshape(1, 25200, 6)[0] # 模型推理后处理 pred = detect_postprocess(pred, frame.shape, [640, 640, 3], conf_thres=0.25, iou_thres=0.45) # 绘制推理结果 res_img = draw_detect_res(frame, pred) # cvs.imshow(res_img) # 测试结果展示停顿 #time.sleep(5) # 图片裁剪,提取车辆目标区域 extract_detect_res(frame, pred, image_name) # cvs.imshow(cut_img) # cap.release() # cv2.destroyAllWindows()
(2)整体业务功能串联
有了前面的对抗样本,即一张图片中其实暗藏着安全风险的图片。
这时就将前面的业务逻辑串联,判断每一个车辆是正常图片还是有安全风险的图片。
如果是正常图片,就进入后面的车辆分类的判断,如果是有安全风险的图片,则通过喵提醒来进行告警。
那么整体业务功能串联,主要包含以下几个部分:
a.车辆检测+检测框小图提取。
ef extract_detect_res(img, all_boxes, image_name, save_folder=None): ''' 检测结果提取 ''' assert save_folder != None, '请输入保存地址!'img = img.astype(np.uint8) color_step = int(255/len(all_boxes)) img_name_lst = [] for bi in range(len(all_boxes)): if len(all_boxes[bi]) == 0: continue count = 0 for box in all_boxes[bi]: x, y, w, h = [int(t) for t in box[:4]] #cv2.putText(img, f'{coco_class[bi]}', (x, y), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2) #cv2.rectangle(img, (x,y), (x+w, y+h),(0, bi*color_step, 255-bi*color_step),thickness = 2) cut_img = img[y:(y+h), x:(x + w)] cv2.imwrite(f'{save_folder}' \ + image_name + "_" + str(count) + ".jpg",cut_img) img_name_lst.append(image_name + "_" + str(count) + ".jpg") count += 1 # cvs.imshow(cut_img) return img_name_lst
(3)对抗攻击
有了车辆区域后,就可以模拟真实的场景,模拟外部用户对模型进行攻击,使得模型识别的能力出现错乱。这里使用基于迁移的黑盒攻击,通过攻击算法生成车辆区域对抗样本,最后将对抗样本给到常规的识别模型即可完成攻击,具体的生成车辆区域对抗样本的代码见Lesson5_code/adv_code/black_attack.py,其中主要代码如下:
### 常规模型加载 # model = mobilenet_v2(pretrained=True) model = mobilenet_v2(pretrained=None) pretrain_param = torch.load('model/mobilenet_v2-b0353104.pth') model.load_state_dict(pretrain_param) model.eval() model = nn.Sequential(normalize, model) model = model.to(device)替身模型加载
model_su = resnet18(pretrained=True)
model_su = resnet18(pretrained=False)
resnet18_param = torch.load(‘model/resnet18-5c106cde.pth’)
model_su.load_state_dict(resnet18_param)
model_su.eval()
model_su = nn.Sequential(normalize, model_su)
model_su = model_su.to(device)对抗攻击:PGD攻击算法
adversary = LinfPGDAttack(
model_su, eps=8/255, eps_iter=2/255, nb_iter=80,
rand_init=True, targeted=False)
adversary = FGSM(
model_su, eps=8/255, eps_iter=2/255, nb_iter=80,
rand_init=True, targeted=False
)from pathlib import Path
src_img_path = Path(‘adv_code/orig_images’)
img_path_lst = [p for p in src_img_path.rglob(‘*’) if p.name.endswith(‘.jpg’)]
for i, img_path in enumerate(img_path_lst):
print(img_path)
### 数据预处理
np_img = get_image(img_path=img_path)
img = torch.tensor(bhwc2bchw(np_img))[None, :, :, :].float().to(device)
imagenet_label2classname = ImageNetClassNameLookup()### 测试模型输出结果 pred = imagenet_label2classname(predict_from_logits(model(img))) print("test output:", pred) ### 输出原label pred_label = predict_from_logits(model_su(img)) # 使用替身模型的相关信息进行对抗样本的获取 # 这包括替身模型的参数、输出label ### 完成攻击,输出对抗样本 advimg = adversary.perturb(img, pred_label) ### 展示源图片,对抗扰动,对抗样本以及模型的输出结果 show_images(model, img, advimg, img_name=f'show_{int(i)}_{pred}.png') ### 迁移攻击样本保存 save_path = "adv_code/adv_results/" torchvision.utils.save_image(advimg.cpu().data, save_path + f"adv_image_{int(i)}_{pred}.png")
(4)整体串联
主代码
if __name__ == '__main__': # 车辆检测# AidLite初始化:调用AidLite进行AI模型的加载与推理,需导入aidlite aidlite = aidlite_gpu.aidlite() # Aidlite模型路径 model_path = 'yolov5_code/aidlux/yolov5_car_best-fp16.tflite' # 定义输入输出shape in_shape = [1 * 640 * 640 * 3 * 4] out_shape = [1 * 25200 * 6 * 4] # 加载Aidlite检测模型:支持tflite, tnn, mnn, ms, nb格式的模型加载 aidlite.ANNModel(model_path, in_shape, out_shape, 4, 0) imgs_path = "yolov5_code/data/images/tests" # 设置测试集路径 images_lst = os.listdir(imgs_path) images_lst = [p for p in images_lst if p.endswith('jpg') or p.endswith('png')] print(images_lst) # extract_res: frame_lst, pred_lst, images_lst extract_res = extract_car_img(imgs_path, images_lst) # 检测框提取 save_folder = "yolov5_code/aidlux/extract_results/" # 图片裁剪,提取车辆目标区域 car_img_name_lst = [] for frame, pred, img_name in zip(*extract_res): img_name_lst = extract_detect_res(frame, pred, img_name, save_folder) car_img_name_lst.extend(img_name_lst) assert car_img_name_lst != [], '没有提取到车辆框!' # 使用对抗样本 # 替身模型加载 normalize = NormalizeByChannelMeanStd( mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # model_su = resnet18(pretrained=True) model_su = resnet18(pretrained=False) resnet18_param = torch.load('model/resnet18-5c106cde.pth') model_su.load_state_dict(resnet18_param) model_su.eval() model_su = nn.Sequential(normalize, model_su) model_su = model_su.to(device) ### 对抗攻击:PGD攻击算法 # adversary = LinfPGDAttack( # model_su, eps=8/255, eps_iter=2/255, nb_iter=80, # rand_init=True, targeted=False) adversary = FGSM( model_su, eps=8/255, targeted=False ) use_advimg = False print(f'是否使用对抗样本: {use_advimg}...') print('车辆框信息:', car_img_name_lst) img_res = [] for i, img_name in enumerate(car_img_name_lst): print(img_name) img_path = save_folder + img_name if use_advimg: advimg, advimg_path = get_advimg(img_path) img_res.append(advimg) else: np_img = get_image(img_path) img = torch.tensor(bhwc2bchw(np_img))[None, :, :, :].float().to(device) img_res.append(img) # AI安全监测与告警 model = Model().eval().to(device) detect_model = Detect_Model().eval().to(device) imagenet_label2classname = ImageNetClassNameLookup() for img in img_res: ### 对抗攻击监测 print(img.size()) detect_pred = detect_model(img) print(detect_pred) if detect_pred > 0.5: id = 'tCOWTW1' # 填写喵提醒中,发送的消息,这里放上前面提到的图片外链 text = "出现对抗攻击风险!!" ts = str(time.time()) # 时间戳 type = 'json' # 返回内容格式 request_url = "http://miaotixing.com/trigger?" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'} result = requests.post(request_url + "id=" + id + "&text=" + text + "&ts=" + ts + "&type=" + type, headers=headers) print('存在风险!') else: pred = imagenet_label2classname(predict_from_logits(model(img))) print('=' * 60) print('result: ', pred)
https://www.bilibili.com/video/BV1Zg411H7LH/
心得与吐槽:
此次学习让我意识到了AI安全的重要性,原来漏洞竟然这么多;学习了本次指挥交通中Ai算法应用的安全及封信防御,对这方面的知识有了更深的了解,感谢ROCKY老师,大白老师,助理。
槽点:需要在社区发布,另外Android6.0.1 安装不了这个软件真的是,助手说的可以装,行不懂。
注:两个黑图是视频,参见AidLux智慧交通——车辆检测&AI安全算法实现流程 - 飞翔的文章 - 知乎
https://zhuanlan.zhihu.com/p/589604206